This integration is powered by Singer's Google Sheets tap and certified by Stitch. Check out and contribute to the repo on GitHub.
For support, contact Support.
Google Sheets integration summary
Stitch’s Google Sheets integration replicates data using the Google Sheets v4 AP1. Refer to the Schema section for a list of objects available for replication.
Stitch’s Google Sheets integration will generate tables containing data related to metadata and the individual sheets within a spreadsheet.
Note: There are a few limitations:
- Currently, the Google Sheets integration replicates one spreadsheet at a time. To replicate another spreadsheet, you will need to create another Google Sheets integration in Stitch.
- The
IMPORTRANGE()function in Google Sheets isn’t currently supported. This integration identifies new and updated data using a spreadsheet’s lastupdated_atvalue, which theIMPORTRANGE()doesn’t update when used.
Google Sheets feature snapshot
A high-level look at Stitch's Google Sheets (v2) integration, including release status, useful links, and the features supported in Stitch.
| STITCH | |||
| Release status |
Deprecated on March 12, 2024 |
Supported by | |
| Stitch plan |
Standard |
API availability |
Not available |
| Singer GitHub repository | |||
| REPLICATION SETTINGS | |||
| Anchor Scheduling |
Supported |
Advanced Scheduling |
Supported |
| Table-level reset |
Unsupported |
Configurable Replication Methods |
Unsupported |
| DATA SELECTION | |||
| Table selection |
Supported |
Column selection |
Supported |
| Select all |
Supported |
||
| TRANSPARENCY | |||
| Extraction Logs |
Supported |
Loading Reports |
Supported |
Connecting Google Sheets
Google Sheets setup requirements
To set up Google Sheets in Stitch, you need:
-
A spreadsheet in your Google Drive.
-
A header row with unique column values in the first row of every sheet you want to replicate. If there are multiple headers not in the first row, your worksheet data may not be replicated correctly. Headers that aren’t in the first row may be extracted as column data.
-
A full row of data in the second row of every sheet you want to replicate. Data must begin in the second row of the sheet. Values in this row may not be
NULLor issues will arise during Extraction.
Step 1: Obtain your spreadsheet ID
- Go to Google Sheets and log into the Google account associated with the spreadsheet you are looking to integrate.
- Open the spreadsheet that you want to use in the integration.
- The Spreadsheet ID is within the URL to the webpage. In the image below, the portion of the URL within the blue box is the Spreadsheet ID. Keep this readily available to continue with the integration.

Step 2: Add Google Sheets as a Stitch data source
- Sign into your Stitch account.
-
On the Stitch Dashboard page, click the Add Integration button.
-
Click the Google Sheets icon.
-
Enter a name for the integration. This is the name that will display on the Stitch Dashboard for the integration; it’ll also be used to create the schema in your destination.
For example, the name “Stitch Google Sheets” would create a schema called
stitch_google_sheetsin the destination. Note: Schema names cannot be changed after you save the integration. - In the Spreadsheet ID field, enter your Spreadsheet ID you obtained from the previous step. Note: To integrate another spreadsheet, you’ll need to repeat these steps over again with another Google Sheets integration.
Step 3: Define the historical replication start date
The Sync Historical Data setting defines the starting date for your Google Sheets integration. This means that data equal to or newer than this date will be replicated to your data warehouse.
Change this setting if you want to replicate data beyond Google Sheets’s default setting of 1 year. For a detailed look at historical replication jobs, check out the Syncing Historical SaaS Data guide.
Step 4: Create a replication schedule
In the Replication Frequency section, you’ll create the integration’s replication schedule. An integration’s replication schedule determines how often Stitch runs a replication job, and the time that job begins.
Google Sheets integrations support the following replication scheduling methods:
-
Advanced Scheduling using Cron (Advanced or Premium plans only)
To keep your row usage low, consider setting the integration to replicate less frequently. See the Understanding and Reducing Your Row Usage guide for tips on reducing your usage.
Step 5: Authorize Stitch
- Next, you’ll be prompted to log into your Google account and approve Stitch’s access to your Google Sheets data. Note that we will only ever read your data.
- Select the See all your Google Sheets spreadsheets access.
- Click Continue.
Step 6: Set objects to replicate
The last step is to select the tables and columns you want to replicate. Learn about the available tables for this integration.
Note: If a replication job is currently in progress, new selections won’t be used until the next job starts.
For Google Sheets integrations, you can select:
-
Individual tables and columns
-
All tables and columns
Click the tabs to view instructions for each selection method.
- In the integration’s Tables to Replicate tab, locate a table you want to replicate.
-
To track a table, click the checkbox next to the table’s name. A blue checkmark means the table is set to replicate.
-
To track a column, click the checkbox next to the column’s name. A blue checkmark means the column is set to replicate.
- Repeat this process for all the tables and columns you want to replicate.
- When finished, click the Finalize Your Selections button at the bottom of the screen to save your selections.
- Click into the integration from the Stitch Dashboard page.
-
Click the Tables to Replicate tab.
- In the list of tables, click the box next to the Table Names column.
-
In the menu that displays, click Track all Tables and Fields:
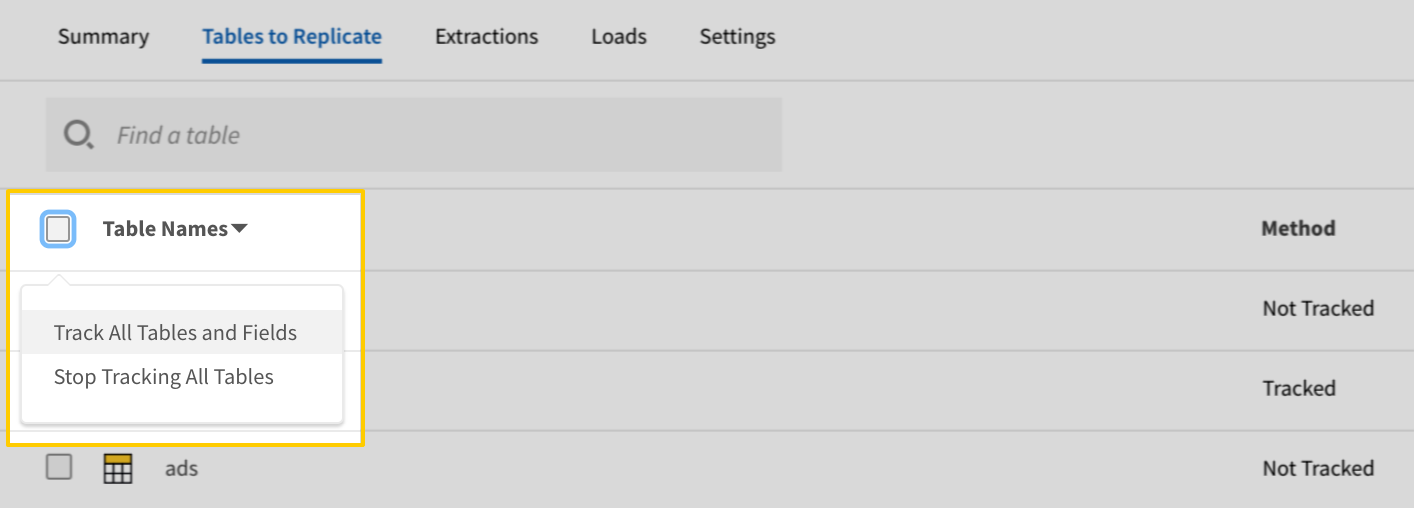
- Click the Finalize Your Selections button at the bottom of the page to save your data selections.
Initial and historical replication jobs
After you finish setting up Google Sheets, its Sync Status may show as Pending on either the Stitch Dashboard or in the Integration Details page.
For a new integration, a Pending status indicates that Stitch is in the process of scheduling the initial replication job for the integration. This may take some time to complete.
Initial replication jobs with Anchor Scheduling
If using Anchor Scheduling, an initial replication job may not kick off immediately. This depends on the selected Replication Frequency and Anchor Time. Refer to the Anchor Scheduling documentation for more information.
Free historical data loads
The first seven days of replication, beginning when data is first replicated, are free. Rows replicated from the new integration during this time won’t count towards your quota. Stitch offers this as a way of testing new integrations, measuring usage, and ensuring historical data volumes don’t quickly consume your quota.
Google Sheets replication
In this section:
-
Details about Extraction, including object discovery and selecting data for replication
-
Details about how data replicated from Google Sheets is loaded into a destination
Extraction
For every table set to replicate, Stitch will perform the following during Extraction:
Discovery
During Discovery, Stitch will:
Determining table schemas
At the start of each replication job, Stitch will check the sheets’s header row and first data row (the second row in the sheet) for data.
To be detected and properly replicated, every sheet set to replicate must have:
-
Column headers with unique values in the first row. If there are duplicate column names, Stitch will skip the sheet and surface a duplicate column name error.
For example: Two columns in the header row can’t be named
customer_id. Uniqueness must not rely on case. Whilecustomer_idandCustomer_IDmay be unique due to case differences, this may still cause errors during extraction and loading. For this reason, column names must be completely unique. -
A full row of data in the second row. If any column in this row is empty but has a format (currency or datetime for example), the type will be determined using the format. If a cell is empty and has no format, the column type will be set to string by default.
If the sheet doesn’t contain a header row and a second row of data, Stitch will skip the sheet and surface an empty sheet message during extraction.
Data typing
To determine data types, Stitch will analyze the first two rows in the files included in object discovery.
If a column contains non-standard boolean language, Stitch will intentionally coerce those values into boolean. The following values are to be expected to be replicated as True:
YES/yesY/y1true(the string “true” prefixed with a tick [`])
The following values are expected to be replicated as False:
NO/noN/n0false(the string “false” prefixed with a tick [`])
If a column has been specified as a STRING, Stitch will attempt to parse the value as a string, unless the column contains non-standard boolean language. If this fails, the column will be loaded as a nullable STRING.
For all other columns, Stitch will perform the following to determine the column’s data type:
- Check the format of the column and parse the value based on that format.
- If that fails, attempt to parse the value as a
BOOLEANvalue - If that fails, attempt to parse the value as an
INTEGER - If that fails, attempt to parse the value as a
DATE-TIMEvalue - If that fails, attempt to parse the value as a
DATEdate - If that fails, attempt to parse the value as a
TIMEvalue - If that fails, type the column as a
STRING
Data replication
After discovery is completed, Stitch will move onto extracting data from the sheets set to replicate.
While data from Google Sheets integrations is replicated using Key-based Incremental Replication, the behavior for this integration differs subtly from other integrations.
The table below compares Key-based Incremental Replication and Replication Key behavior for Google Sheets to that of other integrations.
| Google Sheets | Other integrations | |
| What's replicated during a replication job? |
The entire contents of a modified spreadsheet. This includes all sheets in the spreadsheet that are set to replicate, regardless of whether they have been modified. |
Only new or updated rows in a table. |
| What's used as a Replication Key? |
The time a spreadsheet is modified. |
A column or columns in a table. |
| Are Replication Keys inclusive? |
No. Only spreadsheets with a modification timestamp value greater than the last saved bookmark are replicated. |
Yes. Rows with a Replication Key value greater than or equal to the last saved bookmark are replicated. |
To reduce row usage, consider scheduling the integration to replicate less frequently.
Loading
For every sheet you set to replicate, Stitch will create a table in your destination. These tables will contain the columns you select for replication, along with some system columns created by Stitch. Refer to the sample table in the next section for an example.
Google Sheets table reference
Schemas and versioning
Schemas and naming conventions can change from version to version, so we recommend verifying your integration’s version before continuing.
The schema and info displayed below is for version 2 of this integration.
Table and column names in your destination
Depending on your destination, table and column names may not appear as they are outlined below.
For example: Object names are lowercased in Redshift (CusTomERs > customers), while case is maintained in PostgreSQL destinations (CusTomERs > CusTomERs). Refer to the Loading Guide for your destination for more info.
file_metadata
The file_metadata table contains metadata about the spreadsheet defined in the integration’s settings.
|
Key-based Incremental |
|
|
Primary Key |
id |
|
Replication Key |
modifiedTime |
| Useful links |
|
createdTime DATE-TIME |
|||
|
driveId STRING |
|||
|
id
STRING |
|||
|
lastModifyingUser OBJECT
|
|||
|
modifiedTime
DATE-TIME |
|||
|
name STRING |
|||
|
teamDriveId STRING |
|||
|
version INTEGER |
sheet_metadata
The sheet_metadata table contains metadata about the sheets within the spreadsheet defined in the integration’s settings.
|
Full Table |
|
|
Primary Key |
sheetId |
| Useful links |
|
columns
ARRAY
|
|||||||
|
gridProperties OBJECT
|
|||||||
|
index INTEGER |
|||||||
|
sheetId
INTEGER |
|||||||
|
sheetType STRING |
|||||||
|
sheetUrl STRING |
|||||||
|
spreadsheetId STRING |
|||||||
|
title STRING |
sheets_loaded
The sheets_loaded table contains metadata about individual sheets loaded to your destination.
|
Full Table |
|
|
Primary Keys |
sheetId spreadsheetId loadDate |
| Useful links |
|
lastRowNumber INTEGER |
|
loadDate
DATE-TIME |
|
sheetId
INTEGER |
|
spreadsheetId
STRING |
|
title STRING |
spreadsheet_metadata
The spreadsheet_metadata table contains metadata about the spreadsheet defined in the integration’s settings.
|
Full Table |
|
|
Primary Key |
spreadsheetId |
| Useful links |
|
properties OBJECT
|
||||
|
spreadsheetId
STRING |
||||
|
spreadsheetUrl STRING |
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.