This integration is powered by Singer's FullStory tap. For support, visit the GitHub repo or join the Singer Slack.
FullStory integration summary
Stitch’s FullStory integration relies on the Data Export pack add-on to replicate data through the FullStory Data Export REST API. Refer to the Schema section for a list of objects available for replication.
FullStory feature snapshot
A high-level look at Stitch's FullStory (v1) integration, including release status, useful links, and the features supported in Stitch.
| STITCH | |||
| Release status |
Released on June 27, 2018 |
Supported by | |
| Stitch plan |
Standard |
API availability |
Available |
| Singer GitHub repository | |||
| REPLICATION SETTINGS | |||
| Anchor Scheduling |
Supported |
Advanced Scheduling |
Supported |
| Table-level reset |
Unsupported |
Configurable Replication Methods |
Unsupported |
| DATA SELECTION | |||
| Table selection |
Unsupported |
Column selection |
Unsupported |
| Select all |
Unsupported |
||
| TRANSPARENCY | |||
| Extraction Logs |
Supported |
Loading Reports |
Supported |
Connecting FullStory
FullStory setup requirements
To set up FullStory in Stitch, you need:
-
A FullStory account with the Data Export Pack add-on. The Data Export Pack is a paid add-on for FullStory accounts that enables you to export raw event data.
This add-on is required to replicate data using FullStory’s Data Export REST API.
Step 1: Retrieve your FullStory API key
- Sign into your FullStory account.
- Click the user menu (three dots, upper right corner) > Settings.
- Click Integrations & API Keys in the menu on the left side of the page.
-
Click API Key:
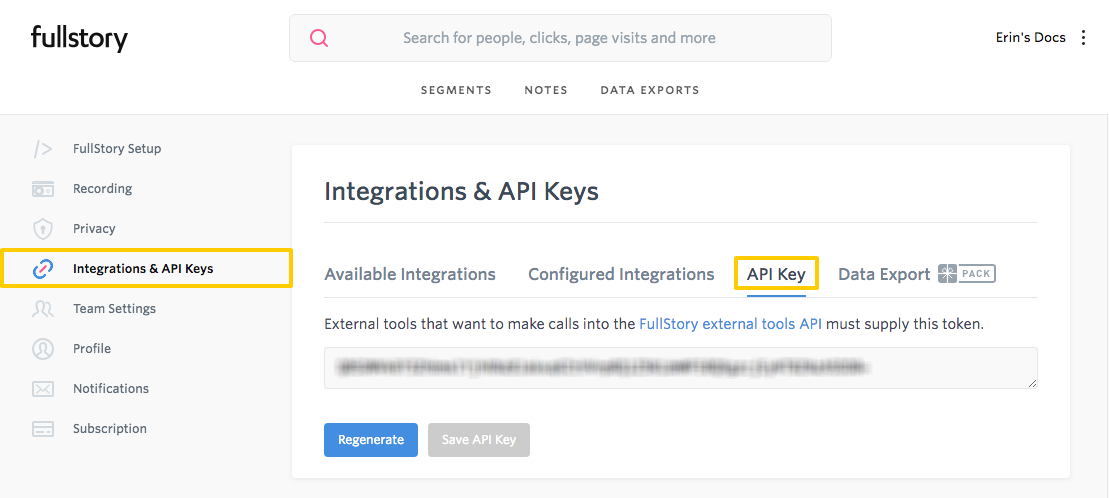
- Your API key will display on the page. Copy the API key before closing the page.
Step 2: Add FullStory as a Stitch data source
- Sign into your Stitch account.
-
On the Stitch Dashboard page, click the Add Integration button.
-
Click the FullStory icon.
-
Enter a name for the integration. This is the name that will display on the Stitch Dashboard for the integration; it’ll also be used to create the schema in your destination.
For example, the name “Stitch FullStory” would create a schema called
stitch_fullstoryin the destination. Note: Schema names cannot be changed after you save the integration. - In the API Key field, paste your FullStory API key.
Step 3: Define the historical replication start date
The Sync Historical Data setting defines the starting date for your FullStory integration. This means that data equal to or newer than this date will be replicated to your data warehouse.
Change this setting if you want to replicate data beyond FullStory’s default setting of 1 year. For a detailed look at historical replication jobs, check out the Syncing Historical SaaS Data guide.
Step 4: Create a replication schedule
In the Replication Frequency section, you’ll create the integration’s replication schedule. An integration’s replication schedule determines how often Stitch runs a replication job, and the time that job begins.
FullStory integrations support the following replication scheduling methods:
-
Advanced Scheduling using Cron (Advanced or Premium plans only)
To keep your row usage low, consider setting the integration to replicate less frequently. See the Understanding and Reducing Your Row Usage guide for tips on reducing your usage.
Initial and historical replication jobs
After you finish setting up FullStory, its Sync Status may show as Pending on either the Stitch Dashboard or in the Integration Details page.
For a new integration, a Pending status indicates that Stitch is in the process of scheduling the initial replication job for the integration. This may take some time to complete.
Initial replication jobs with Anchor Scheduling
If using Anchor Scheduling, an initial replication job may not kick off immediately. This depends on the selected Replication Frequency and Anchor Time. Refer to the Anchor Scheduling documentation for more information.
Free historical data loads
The first seven days of replication, beginning when data is first replicated, are free. Rows replicated from the new integration during this time won’t count towards your quota. Stitch offers this as a way of testing new integrations, measuring usage, and ensuring historical data volumes don’t quickly consume your quota.
FullStory replication
Data updates and FullStory data export bundles
FullStory data bundles event data together based on a time period setting you define. By default, a FullStory data bundle contains data about events that occurred during a 24 hour period.
Note: FullStory makes event bundles available 24 hours the last event in the bundle occurs.
For example: If your bundle period is set to 6 hours, a data export bundle for events that occur on June 1 between 12:00PM - 6:00PM will be available the following day, June 2, at 6:00PM.
Impact on Stitch replication
Because FullStory only makes event data available a full day after events have occurred, records for the current date will only ever be available the next day. Event data that is one day old is considered “up to date” for this integration.
Loading data using Append-Only loading
When Stitch loads the extracted data for FullStory events into your destination, it will do so using Append-Only loading. This is a type of loading behavior where existing rows aren’t updated, but appended to the end of the table. Note: Loading will be append-only even if the destination you’re using supports Upsert loading.
Refer to the Understanding loading behavior guide for more info and examples.
For FullStory, this means that every captured event is equal to a single row in the events table. Using this data, you can view a given user’s event history and construct a timeline of their actions.
Example: Create a user session timeline
The table below contains what sample data might look like for a user who changes their address during a session:

Using this data, we can put together the order of events for this user’s session:
- The user clicks (
EventType: click) theUpdate Addressbutton on the page athttps://example.com/my-account. - Next, the user clicks in the
Street addresstext field on the page athttps://example.com/update-address. - The user changes (
EventType: change) the text in theStreet addressfield to1339 Chestnut Streeton the page athttps://example.com/update-address. - Lastly, the user clicks the
Save Changesbutton on the page athttps://example.com/update-address.
FullStory table reference
Schemas and versioning
Schemas and naming conventions can change from version to version, so we recommend verifying your integration’s version before continuing.
The schema and info displayed below is for version 1 of this integration.
This is the latest version of the FullStory integration.
Table and column names in your destination
Depending on your destination, table and column names may not appear as they are outlined below.
For example: Object names are lowercased in Redshift (CusTomERs > customers), while case is maintained in PostgreSQL destinations (CusTomERs > CusTomERs). Refer to the Loading Guide for your destination for more info.
events
The events table contains raw data about the events that occurred on your site, which are recorded using the FullStory JavaScript library.
Note: Records for this table are loaded using Append-Only loading. Loading will be append-only even if the destination you’re using supports Upsert loading.
|
Key-based Incremental |
|
|
Primary Key |
__sdc_primary_key |
|
Replication Key |
EventStart |
| Useful links |
|
EventStart
DATE-TIME |
|
EventTargetSelectorTok STRING |
|
EventTargetText STRING |
|
EventType STRING |
|
IndvId INTEGER |
|
PageActiveDuration INTEGER |
|
PageAgent STRING |
|
PageBrowser STRING |
|
PageDevice STRING |
|
PageDuration INTEGER |
|
PageId INTEGER |
|
PageIp STRING |
|
PageLatLong STRING |
|
PageNumErrors INTEGER |
|
PageNumInfos INTEGER |
|
PageNumWarnings INTEGER |
|
PageOperatingSystem STRING |
|
PageRefererUrl STRING |
|
PageUrl STRING |
|
SessionId INTEGER |
|
UserAppKey STRING |
|
UserDisplayName STRING |
|
UserEmail STRING |
|
UserId INTEGER |
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.