Welcome to Stitch!
Stitch is a cloud-first, open source platform for rapidly moving data. A simple, powerful ETL service, Stitch connects to all your data sources – from databases like MySQL and MongoDB, to SaaS applications like Salesforce and Zendesk – and replicates that data to a destination of your choosing.
In this guide, we’ll cover the basic concepts and architecture of Stitch, including:
-
What Stitch does, how to get set up, and how usage is calculated
-
A step-by-step tour of the Stitch system, from data extracted to data loaded
Basics
What is Stitch?
Stitch a cloud-based, ETL data pipeline. ETL is short for extract, transform, load, which are the steps in a process that moves data from a source to a destination.
That being said, keep in mind that Stitch isn’t:
- A data analysis service. We have many analytics partners who can help here, however.
- A data visualization or querying tool. Stitch only moves data. To analyze it, you’ll need an additional tool. Refer to our list of analysis tools for some suggestions.
- A destination. A destination is typically a data warehouse and is required to use Stitch. While we can’t create one for you, you can use our Choosing a destination guide if you need some help picking the right destination for your needs.
Get set up
In just a few minutes, you can set up your own data pipeline:
- Sign up for a Stitch account. Don’t have an account yet? Sign up here for your free trial.
- Connect a destination. A destination, typically a database or data warehouse, where Stitch will load the replicated data. This includes products like Amazon Redshift, Amazon S3, or Google BigQuery.
- Connect an integration. Integrations are data sources, or where Stitch replicates data from. This includes SaaS applications like Google Analytics, databases like MySQL, and more.
For a step-by-step look at setting up Stitch, refer to the Setting up your Stitch data pipeline guide.
Integrations and destinations
To use Stitch, you need a destination and at least one integration, or data source.
Destinations
Stitch supports some of the most popular data lakes, warehouses, and storage platforms as destinations, such as Amazon Redshift, Google BigQuery, and Microsoft Azure Synapse Analytics.
The destination you choose determines how replicated data is loaded and structured. This is discussed in more detail in the Transformations section.
Refer to the Destination documentation for more info on each of Stitch’s destination offerings. If you’re new to data warehousing or you want to see how Stitch’s destination offerings compare to each other, check out our Choosing a Destination guide. This guide will help you choose the best Stitch destination for your data warehousing needs, from ensuring your data sources are compatible to staying within your budget.
Integrations
An integration is a data source. This can be a database, API, file, or other data application that Stitch replicates data from, such as MySQL, Google Analytics, or Amazon S3.
During your free trial, all of Stitch’s integrations are accessible. After the trial ends, some integrations - such as Oracle or Google Analytics 360 - are only available if you enter into an Advanced or Premium plan.
Refer to the Integration documentation for more info on each of Stitch’s integrations, such as what data is available or what features are supported.
Rows and Stitch usage
Stitch usage is volume-based. Much like the data part of a cell phone plan, each Stitch plan includes a set number of replicated rows per month. Your overall row usage can be affected by a variety of factors, including the destination you choose and number of integrations you have.
For an in-depth walkthrough of how usage is calculated, the factors that affect it, and how you can reduce your usage, refer to the Understanding and Reducing Your Usage guide.
Replication
Stitch’s replication process consists of three distinct phases:
- Extract: Stitch pulls data from your data sources and persists it to Stitch’s data pipeline through the Import API.
- Prepare: Data is lightly transformed to ensure compatibility with the destination.
- Load: Stitch loads the data into your destination.
A single occurrence of these three phases is called a replication job. You can keep an eye on a replication job’s progress on any integration’s Summary page.
Extraction settings
When you set up an integration in Stitch, you’ll also need to define its replication settings. These settings control the Extraction phase of the replication process, including how often Extraction occurs, what data should be extracted, and how data is extracted.
Time to data loaded
Because our process is performed in steps, it’s important to note that Stitch replication isn’t real-time. This means that there will be some time between data extracted and data loaded, which you can read more about in the System architecture section of this guide.
Additionally, the speed of Extraction and Loading is largely dependent on the resources available in your data sources and destination.
Deleted records
Stitch will never delete data from your destination, even if records have been deleted from the source. Refer to the Deleted Record Handling guide for more info and examples.
Transformations
Stitch’s goal is to get data from your data sources to your destination in a useful, raw format:
Useful means with types and structures that make the data easy to work with, and raw means staying as close to the original representation as possible.
This doesn’t mean that Stitch doesn’t perform transformations during the replication process. Stitch just doesn’t perform arbitrary transformations - Stitch will perform only the transformations required to ensure the loaded data is useful and compatible with your destination. The transformations Stitch performs are dependent on the destination you choose. These can include:
Stitch’s philosophy is that what you do with your data depends on your needs, and by keeping data close to its original form, Stitch enables you to manage and transform it as you see fit. While we don’t support user-defined transformations inside of Stitch, you can take advantage of Talend’s transformation and data quality solutions to design and integrate your own transformations.
Data typing
Stitch’s data typing process consists of three steps which take place during replication:
- Extraction: Identify the data type in the source
- Preparing: Map the data type to a Stitch data type
- Loading: Convert the Stitch data type to a destination-compatible data type
Stitch converts data types only where needed to ensure the data is accepted by your destination.
With some exceptions, when a data type is changed or a field has multiple data types in the source, Stitch will create an additional column in the destination to accommodate the new data type. This will look like the column has been “split”. For example:
| id | has_magic__bo | has_magic__st |
| 1 | true | |
| 2 | yes | |
| 3 | no |
Stitch handles changed data types in this way to ensure previously loaded data is retained in its original format. Some Stitch customers use views to coerce data types when this occurs.
Refer to the Columns with mixed data types guide for more info and examples.
JSON structures
The destination you’re using determines how Stitch handles complex JSON structures such as arrays and objects.
If your destination natively supports storing nested data, Stitch will store the data as a type appropriate for storing semi-structured data. You can then use the JSON functions supported by the destination to parse and analyze the data.
If your destinaton doesn’t natively support storing nested data, Stitch will “de-nest”, or normalize, the data into relations. For JSON objects, attributes will be flattened into the table, while arrays will be unpacked into subtables. For more info and examples, refer to the Nested JSON structures guide.
Object names
When you initially set up an integration, you’ll define the name of the schema in the destination where Stitch will load that integration’s data.
The names of the tables and columns you set to replicate, however, are automatically generated based on two factors:
- The name of the object in the source
- The object naming rules enforced by the destination
During loading, Stitch will attempt to keep object names as close to the source as possible. Some transformations may occur to ensure that the object name conforms to the destination’s naming rules.
Note: Table and column names cannot be changed in Stitch.
Timezones
Some of the destinations Stitch offers don’t natively support timezones. To ensure accuracy and consistency, Stitch handles data with timezones in this manner:
- Extract the data from the source
- Convert the source data to UTC
- Load the data as UTC into your destination
Depending on the destination you’re using, the data may or may not be stored with the timezone information. This is dependent on whether the destination supports timezones.
For more info, refer to the loading reference for your destination.
System architecture
Now that you understand the basics of Stitch and how data replication works, let’s take a look at the internal workings of the Stitch system.
Stitch’s replication process consists of three phases:
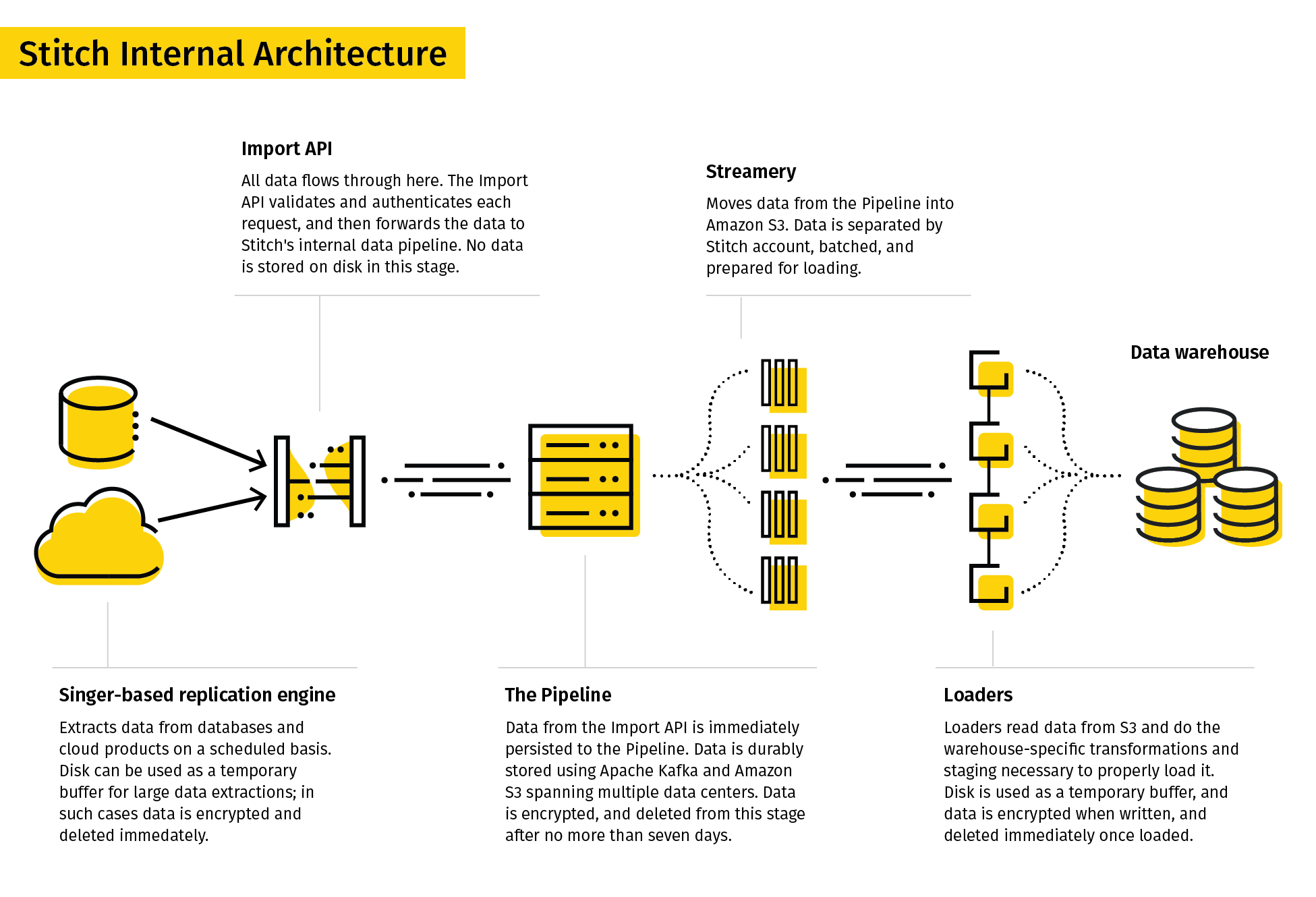
Note: This process is the same regardless of your account’s data pipeline region.
Extract
The first phase in the replication process is called Extract. During this phase, data is extracted from an integration using the replication settings you define.
The Extract phase includes:
Step 1: The Singer-based replication engine
For SaaS applications and databases, data is pulled on a schedule using the Singer-based replication engine that Stitch runs against data sources like APIs, databases, and flat files.
During this step, two things happen:
-
A structure sync. At the start of every extraction, Stitch will run what is called a structure sync. A structure sync detects the tables and columns available in the source, along with any changes to the structure of those tables and columns.
Note: New tables and columns detected during a structure sync will be available in Stitch after the current replication job ends. For the majority of integrations, new tables and columns won’t be automatically set to replicate.
-
Data is extracted in JSON format. Based on the schemas, tables, and columns set to replicate, Stitch extracts the data in JSON format and sends it to the Import API.
Step 2: The Import API
The next step in the replication process is the Import API.
For data sent directly to Stitch through a webhook or Import API integration, this is the first step in the replication process. (Note: This is why webhook and Import API integrations don’t have Extraction Logs.)
The Import API validates and authenticates each request, and then persists the data to Stitch’s internal data pipeline.
If the data fails validation or another critical error occurs, the extraction will fail and trigger an in-app and email notification. The error can also be viewed in an integration’s Extraction Logs tab.
Prepare
The second phase in the replication process is called Prepare. During this phase, the extracted data is buffered in Stitch’s durable, highly available internal data pipeline and readied for loading.
The Prepare phase includes:
Step 3: The Pipeline
Stitch uses Apache Kafka and Amazon S3 systems spanning multiple data centers to durably buffer the data received by the Import API, and ensure we meet our most important service-level target: don’t lose data. Data is always encrypted at rest, and automatically deleted from the buffer after no more than seven days.
Step 4: The Streamery
Next, data is read from the pipeline and separated, batched, and prepared for loading by an internal Stitch service called the Streamery.
The Streamery writes data to Amazon S3 that is encrypted, separated by tenant (Stitch account) and data set, and ready to be loaded. Most data is loaded within minutes, but if a destination is unavailable, it can stay in S3 for up to 30 days before being automatically deleted.
Load
The last phase in the replication process is called Load. During this phase, the prepared data is transformed to be compatible with the destination, and then loaded.
The Loading phase includes:
Step 5: The Loaders
A Loader reads data from the Streamery (Amazon S3) and performs the transformations necessary - such as converting data into the appropriate data types or structure - before loading it into your destination. Disk is used as a temporary buffer, data is encrypted when written, and deleted immediately once loaded.
Stitch defaults to using SSL/TLS-encrypted connections to your destination when possible. SSH-encrypted tunnels are also available to be configured for most destination types.
If a critical error occurs, the load will fail and trigger an in-app and email notification. The error can also be viewed in an integration’s Loading Reports tab.
Step 6: Your destination
Data is finally loaded into your destination! For each integration, Stitch will create a schema (or dataset, or folder, or database, depending on your destination) and load that integration’s data into it. Refer to the Understanding integration schema structures guide for info on how schemas will be structured.
At this point, you can use an analysis tool to interact with your data.
Next steps
Now that you’ve mastered the basics, move onto:
-
Setting Up Your Stitch Data Pipeline: Get your Stitch data pipeline up and running.
-
Understanding and Reducing Your Row Usage: Learn the basics of Stitch billing, how to view and understand your usage, and keep your row count low.
-
Connecting Other Data Sources to Stitch: Don’t see an integration you want in Stitch? Learn about your options for getting data from not-currently-supported data sources into Stitch.
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.