This integration is powered by Singer's FrontApp tap. For support, visit the GitHub repo or join the Singer Slack.
Front integration summary
Stitch’s Front integration replicates data using the Front API. Refer to the Schema section for a list of objects available for replication.
Front feature snapshot
A high-level look at Stitch's Front (v1) integration, including release status, useful links, and the features supported in Stitch.
| STITCH | |||
| Release status |
Deprecated on November 29, 2023 |
Supported by | |
| Stitch plan |
Standard |
API availability |
Not available |
| Singer GitHub repository | |||
| REPLICATION SETTINGS | |||
| Anchor Scheduling |
Supported |
Advanced Scheduling |
Supported |
| Table-level reset |
Unsupported |
Configurable Replication Methods |
Unsupported |
| DATA SELECTION | |||
| Table selection |
Supported |
Column selection |
Supported |
| Select all |
Supported |
||
| TRANSPARENCY | |||
| Extraction Logs |
Supported |
Loading Reports |
Supported |
Connecting Front
Front setup requirements
To set up Front in Stitch, you need:
-
A Premium or Enterprise Front plan. These plans include API access, which is required to use Stitch’s Front integration. Refer to Front’s pricing page for more info.
Step 1: Generate a Front API token
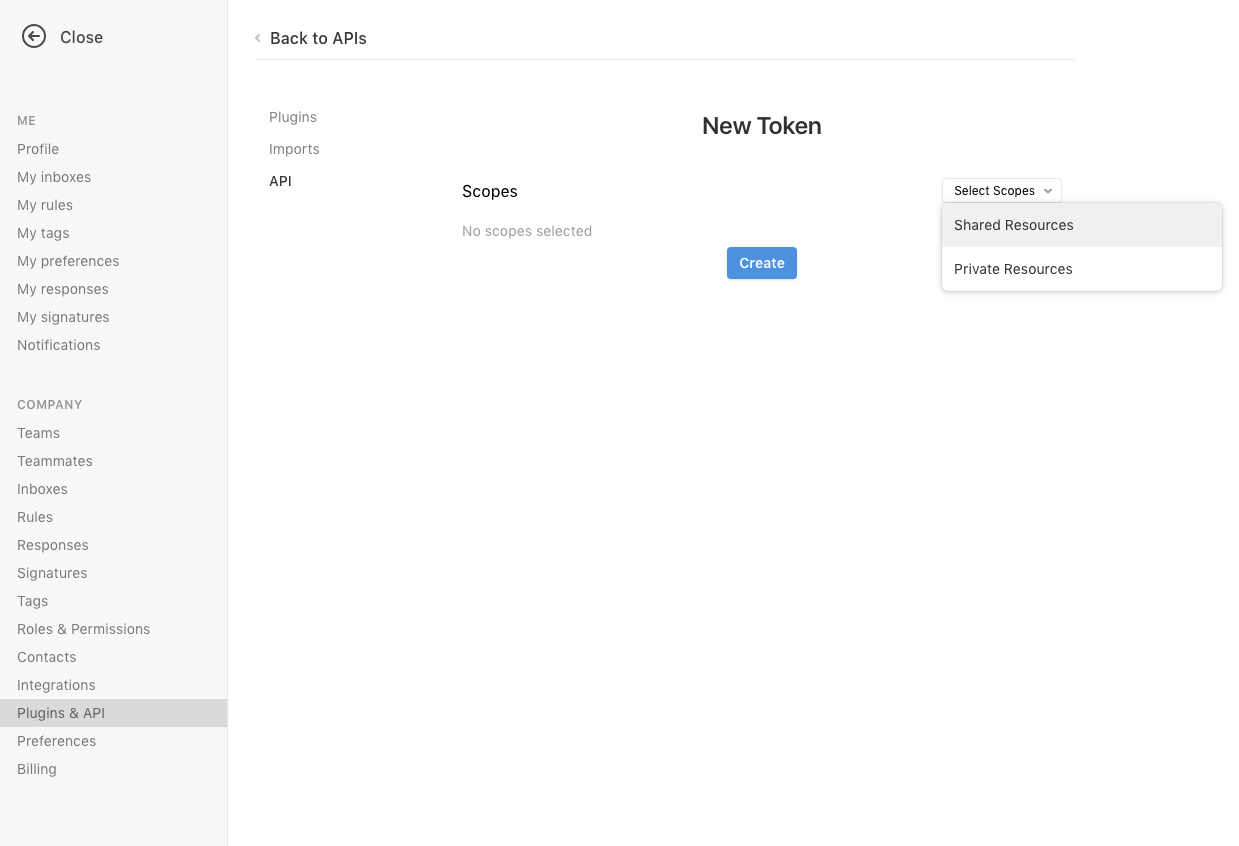
- Sign into your Front account.
- Click the user menu (your icon) in the top left corner of the page.
- Click Settings.
- In the Company section on the left side of the page, click Plugins & API.
- On the page that displays, click API.
- Click the New Token button.
- On the New Token page, click the Select Scopes dropdown and select the type of resources you want to replicate data from.
- Click Create to create the API token.
Keep the token handy - you’ll need it in the next step to complete the setup.
Step 2: Add Front as a Stitch data source
- Sign into your Stitch account.
-
On the Stitch Dashboard page, click the Add Integration button.
-
Click the Front icon.
-
Enter a name for the integration. This is the name that will display on the Stitch Dashboard for the integration; it’ll also be used to create the schema in your destination.
For example, the name “Stitch Front” would create a schema called
stitch_frontin the destination. Note: Schema names cannot be changed after you save the integration. - In the API Token field, paste the Front API token you generated in Step 1.
- From the Incremental Range dropdown, select one of the following options:
- Daily - Data will be aggregated on a daily basis.
- Hourly - Data will be aggregated on an hourly basis.
Step 3: Define the historical replication start date
The Sync Historical Data setting defines the starting date for your Front integration. This means that data equal to or newer than this date will be replicated to your data warehouse.
Change this setting if you want to replicate data beyond Front’s default setting of 1 year. For a detailed look at historical replication jobs, check out the Syncing Historical SaaS Data guide.
Step 4: Create a replication schedule
In the Replication Frequency section, you’ll create the integration’s replication schedule. An integration’s replication schedule determines how often Stitch runs a replication job, and the time that job begins.
Front integrations support the following replication scheduling methods:
-
Advanced Scheduling using Cron (Advanced or Premium plans only)
To keep your row usage low, consider setting the integration to replicate less frequently. See the Understanding and Reducing Your Row Usage guide for tips on reducing your usage.
Step 5: Set objects to replicate
The last step is to select the tables and columns you want to replicate. Learn about the available tables for this integration.
Note: If a replication job is currently in progress, new selections won’t be used until the next job starts.
For Front integrations, you can select:
-
Individual tables and columns
-
All tables and columns
Click the tabs to view instructions for each selection method.
- In the integration’s Tables to Replicate tab, locate a table you want to replicate.
-
To track a table, click the checkbox next to the table’s name. A blue checkmark means the table is set to replicate.
-
To track a column, click the checkbox next to the column’s name. A blue checkmark means the column is set to replicate.
- Repeat this process for all the tables and columns you want to replicate.
- When finished, click the Finalize Your Selections button at the bottom of the screen to save your selections.
- Click into the integration from the Stitch Dashboard page.
-
Click the Tables to Replicate tab.
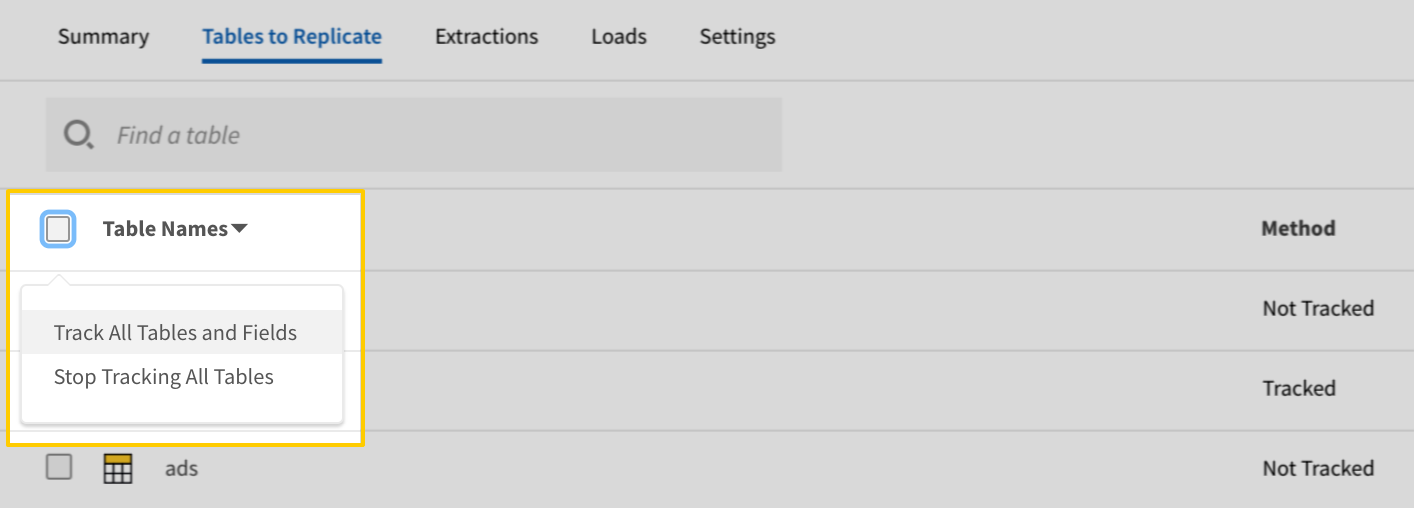
- In the list of tables, click the box next to the Table Names column.
-
In the menu that displays, click Track all Tables and Fields:
- Click the Finalize Your Selections button at the bottom of the page to save your data selections.
Initial and historical replication jobs
After you finish setting up Front, its Sync Status may show as Pending on either the Stitch Dashboard or in the Integration Details page.
For a new integration, a Pending status indicates that Stitch is in the process of scheduling the initial replication job for the integration. This may take some time to complete.
Initial replication jobs with Anchor Scheduling
If using Anchor Scheduling, an initial replication job may not kick off immediately. This depends on the selected Replication Frequency and Anchor Time. Refer to the Anchor Scheduling documentation for more information.
Free historical data loads
The first seven days of replication, beginning when data is first replicated, are free. Rows replicated from the new integration during this time won’t count towards your quota. Stitch offers this as a way of testing new integrations, measuring usage, and ensuring historical data volumes don’t quickly consume your quota.
Front table reference
Schemas and versioning
Schemas and naming conventions can change from version to version, so we recommend verifying your integration’s version before continuing.
The schema and info displayed below is for version 1 of this integration.
Table and column names in your destination
Depending on your destination, table and column names may not appear as they are outlined below.
For example: Object names are lowercased in Redshift (CusTomERs > customers), while case is maintained in PostgreSQL destinations (CusTomERs > CusTomERs). Refer to the Loading Guide for your destination for more info.
customers_table
|
Key-based Incremental |
|
|
Primary Keys |
analytics_date analytics_range resource_t resource_v |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
DATE |
|
analytics_range
STRING |
|
avg_first_response_p NUMBER |
|
avg_first_response_v NUMBER |
|
avg_resolution_p NUMBER |
|
avg_resolution_v NUMBER |
|
avg_response_p NUMBER |
|
avg_response_v NUMBER |
|
num_received_p INTEGER |
|
num_received_v INTEGER |
|
num_sent_p INTEGER |
|
num_sent_v INTEGER |
|
resource_id INTEGER |
|
resource_t
STRING |
|
resource_url STRING |
|
resource_v
STRING |
first_response_histo
|
Key-based Incremental |
|
|
Primary Keys |
analytics_date analytics_range time_v |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
DATE |
|
analytics_range
STRING |
|
replies_p NUMBER |
|
replies_v NUMBER |
|
time_v
STRING |
resolution_histo
|
Key-based Incremental |
|
|
Primary Keys |
analytics_date analytics_range time_v |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
DATE |
|
analytics_range
STRING |
|
resolutions_p NUMBER |
|
resolutions_v NUMBER |
|
time_v
STRING |
response_histo
|
Key-based Incremental |
|
|
Primary Keys |
analytics_date analytics_range time_v |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
DATE |
|
analytics_range
STRING |
|
replies_p NUMBER |
|
replies_v NUMBER |
|
time_v
STRING |
tags_table
The tags_table table contains a list of tag statistics since the last completed replication job through the most recent iteration of the defined Incremental Range (day or hour).
This table will include tags in your Front account.
Note: During the historical replication job, all increments (defined using the Incremental Range setting) since the Start Date will be replicated. This will result in the first record for this table being an aggregated record across all tags.
|
Key-based Incremental |
|
|
Primary Keys |
tag_v analytics_range analytics_date |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
DATE |
|
analytics_range
STRING |
|
avg_message_conversations_p NUMBER |
|
avg_message_conversations_v NUMBER |
|
conversations_archived_p INTEGER |
|
conversations_archived_v INTEGER |
|
conversations_open_p INTEGER |
|
conversations_open_v INTEGER |
|
conversations_total_p INTEGER |
|
conversations_total_v INTEGER |
|
num_messages_p INTEGER |
|
num_messages_v INTEGER |
|
tag_id INTEGER |
|
tag_url STRING |
|
tag_v
STRING |
team_table
The team_table table contains a list of team member statistics since the last completed replication job through the most recent iteration of the defined Incremental Range (day or hour).
This table will include team members from all teams in your Front account.
Note: During the historical replication job, all increments since the Start Date will be replicated. This will result in the first record for this table being an aggregated record across all team members.
|
Key-based Incremental |
|
|
Primary Keys |
analytics_date analytics_range teammate_v |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
OBJECT |
|
analytics_range
OBJECT |
|
avg_first_reaction_time_p OBJECT |
|
avg_first_reaction_time_v OBJECT |
|
avg_message_conversations_p OBJECT |
|
avg_message_conversations_v OBJECT |
|
avg_reaction_time_p OBJECT |
|
avg_reaction_time_v OBJECT |
|
num_composed_p OBJECT |
|
num_composed_v OBJECT |
|
num_conversations_p OBJECT |
|
num_conversations_v OBJECT |
|
num_messages_p OBJECT |
|
num_messages_v OBJECT |
|
num_replied_p OBJECT |
|
num_replied_v OBJECT |
|
num_sent_p OBJECT |
|
num_sent_v OBJECT |
|
teammate_id OBJECT |
|
teammate_p OBJECT |
|
teammate_url OBJECT |
|
teammate_v
OBJECT |
top_conversations_table
|
Key-based Incremental |
|
|
Primary Keys |
analytics_date analytics_range teammate_v |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
DATE |
|
analytics_range
STRING |
|
num_conversations_p INTEGER |
|
num_conversations_v INTEGER |
|
teammate_id INTEGER |
|
teammate_url STRING |
|
teammate_v
STRING |
top_reaction_time_table
|
Key-based Incremental |
|
|
Primary Keys |
analytics_date analytics_range teammate_v |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
DATE |
|
analytics_range
STRING |
|
avg_reaction_time_p NUMBER |
|
avg_reaction_time_v NUMBER |
|
teammate_id INTEGER |
|
teammate_url STRING |
|
teammate_v
STRING |
top_replies_table
|
Key-based Incremental |
|
|
Primary Keys |
analytics_date analytics_range teammate_v |
|
Replication Key |
analytics_date |
| Useful links |
|
analytics_date
DATE |
|
analytics_range
STRING |
|
num_replies_p INTEGER |
|
num_replies_v INTEGER |
|
teammate_id INTEGER |
|
teammate_url STRING |
|
teammate_v
STRING |
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.