Important: This guide is applicable if:
- You’re migrating from an existing Google BigQuery v1 destination to v2 in the same Stitch account
- You previously used your Google BigQuery instance as a Stitch destination and it contains integration datasets (schemas). This instance may have been connected to your current account or a previous account.
If you’re new to Stitch or haven’t used Stitch’s Google BigQuery destination before, refer to the Connecting a Google BigQuery v2 destination guide.
Prerequisites
An existing Google Cloud Platform (GCP) project with the following setup:
-
Enabled billing for the GCP project. The project must have billing enabled and an attached credit card. This is required for Stitch to successfully load data.
-
An existing Google Google BigQuery instance in the GCP project. Stitch will not create an instance for you.
-
Permissions in the GCP project that allow you to create Identity Access Management (IAM) service accounts. Stitch uses a service account during the replication process to load data into Google BigQuery. Refer to Google’s documentation for more info about service accounts and the permissions required to create them.
Considerations
Here’s what you need to know to ensure a smooth switch:
-
Google BigQuery v2 destinations structure data differently than v1. Notably, how nested data and Primary Keys are handled. Refer to the Google BigQuery v2 reference for an in-depth look at Google BigQuery v2.
-
Your integrations will be paused. All database and SaaS integrations will be automatically paused. After the switch is complete, you’ll need to manually unpause the integrations you’d like to resume.
-
Some webhook data may be lost during this process. Due to webhook’s continuous, real-time nature, some data may be lost.
-
We won’t delete or transfer any data from your current destination. To get historical data into your new destination, you’ll need to queue a full re-replication of all your integrations.
Re-replicating historical data will count towards your row usage and may take some time, depending on the volume of data and API limitations imposed by the provider.
-
Historical data from webhook-based integrations must be either manually backfilled or replayed. Some webhook providers - such as Segment - allow customers on certain plans to ‘replay’ their historical data. This feature varies from provider to provider and may not always be available.
If you don’t have the ability to replay historical webhook data, then it must be manually backfilled after the switch is complete.
Step 1: Delete your existing Google BigQuery destination in Stitch
In this step, you’ll delete the current Google BigQuery v1 destination configuration in Stitch:
Step 1.1: Select a historical data setting
- From the Stitch Dashboard, click the Destination tab.
- At the bottom of the page, click the Remove Destination button.
-
In the Connected Source Integrations section, select how you want data to be replicated to the new destination:
-
Replicate new data only: Stitch will pick up where it left off and only replicate new data to your new destination.
-
Replicate historical data: Stitch will clear all Replication Key values, queue a full re-replication of your integrations’ data, and replicate all historical data to your new destination. For SaaS integrations, Stitch will replicate data beginning with the Start Date currently listed in the integration’s settings.
Note: This isn’t applicable to webhook integrations. Historical data for webhooks must be replayed or manually backfilled after the switch is complete.
-
Step 1.2: Delete the existing Google BigQuery destination in Stitch
- In the Confirm Removal field, enter the display name of the destination.
- Click Remove Destination to confirm. You’ll be prompted to confirm the removal of the current destination’s settings.
- To continue with the switch, click Remove to delete the current destination settings.
Note: This will not delete data in the destination itself - it only clears this destination’s settings from Stitch.
Step 2: Delete existing Stitch integration datasets in Google BigQuery
Next, you’ll need to prep your Google BigQuery instance for the migration. To continue replicating data from your existing integrations, you’ll need to delete the integration datasets (schemas) and tables in Google BigQuery and allow Stitch to re-create them using Google BigQuery v2.
For example: Using Google BigQuery v1, data was replicated to an integration dataset named facebook_ads. You want to continue replicating data from this integration to the facebook_ads dataset. To do so, you need to delete the entire facebook_ads dataset and allow Stitch to re-create it using Google BigQuery v2. This is to ensure data is loaded correctly.
Note: This must be completed for every integration dataset created using a Google BigQuery v1 destination where you want to continue replicating data to the same dataset name. Additionally, this is applicable even if another Stitch account was used with Google BigQuery v1. If not completed, Stitch will encounter issues when attempting to load data.
If you want to retain any historical webhook data, create a backup of the data before deleting datasets from your Google BigQuery instance. If you have the ability to replay webhook data, you may not need to do this.
Refer to Google’s documentation for instructions on deleting datasets.
Step 3: Set up Google BigQuery v2
Next, you’ll configure the new Google BigQuery v2 destination in Stitch:
Step 3.1: Create a GCP IAM service account
Step 3.1.1: Define the service account details
- Navigate to the IAM Service Accounts page in the GCP console.
-
Select the project you want to use by using the project dropdown menu, located near the top left corner of the page:
- Click + Create Service Account.
- On the Service account details page, fill in the field as follows:
- Service account name: Enter a name for the service account. For example:
Stitch - Serivce account description: Enter a description for the service account. For example:
Replicate Stitch data
- Service account name: Enter a name for the service account. For example:
- Click Create.
Step 3.1.2: Assign BigQuery Admin permissions
Next, you’ll assign the BigQuery Admin role to the service account. This is required to successfully load data into Google BigQuery.
- On the Service account permissions page, click the Role field.
-
In the window that displays, type
bigqueryinto the filter/search field: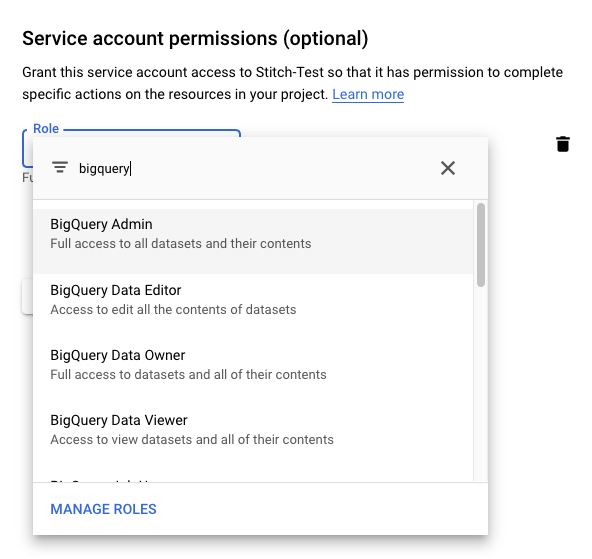
- Select BigQuery Admin.
- Click Continue.
Step 3.1.3: Create a JSON project key
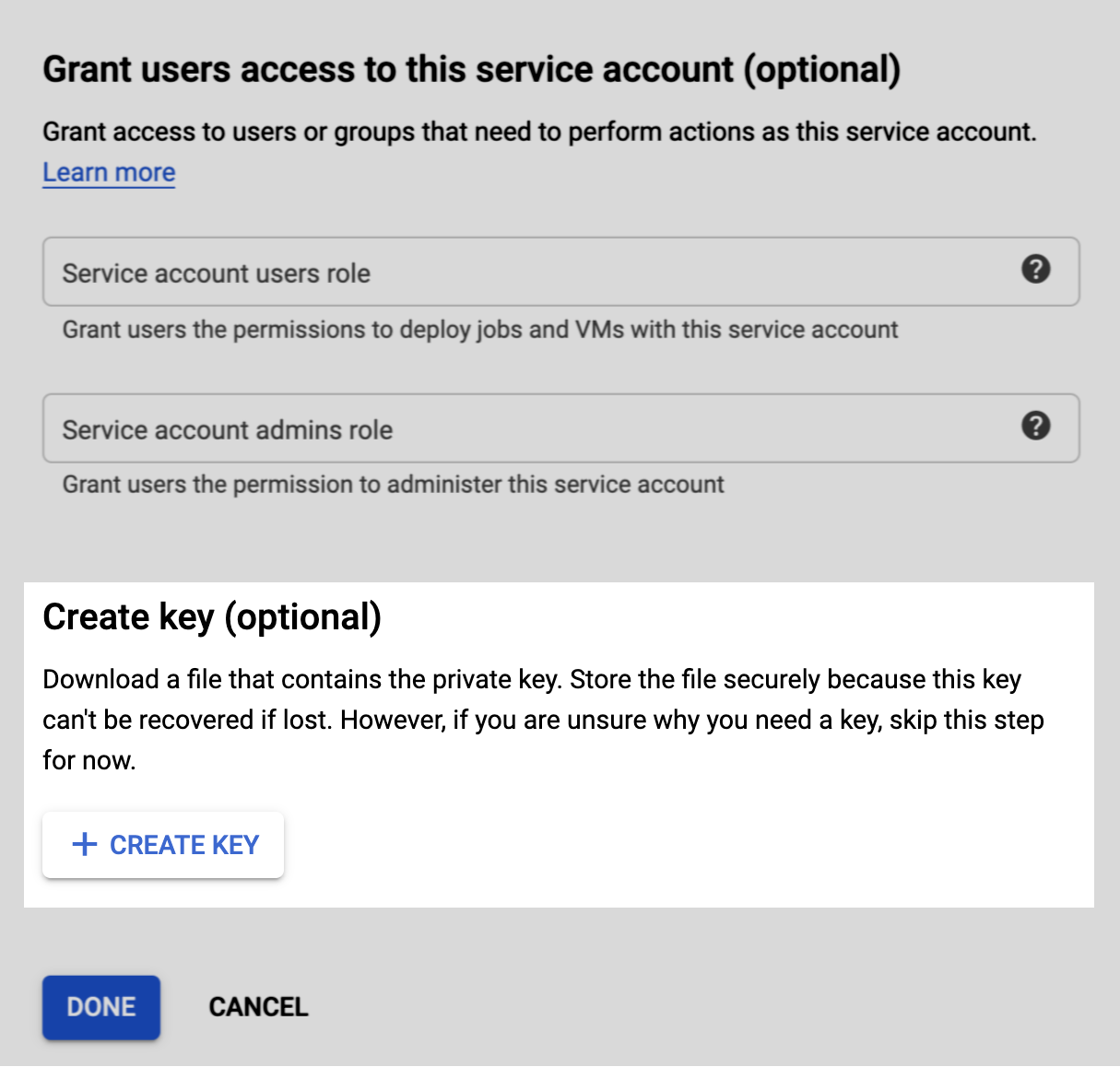
The last step is to create and download a JSON project key. The project key file contains information about the project, which Stitch will use to complete the setup.
- On the Grant users access to this service account page, scroll to the Create key section.
- Click + Create Key.
- When prompted, select the JSON option.
- Click Create.
- Save the JSON project key file to your computer. The file will be downloaded to the location you specify (if prompted), or the default download location defined for the web browser you’re currently using.
Step 3.2: Connect Stitch
To complete the setup, you’ll upload the GCP project key file to Stitch and define settings for your Google BigQuery destination:
Step 3.2.1: Upload the JSON project key file to Stitch
- Navigate back to the page where your Stitch account is open.
-
Click the Google BigQuery icon.
- Scroll to the Your service account section.
- In the Your Key File field, click the
 icon and locate the JSON project key file you created in Step 1.3.
icon and locate the JSON project key file you created in Step 1.3.
Once uploaded, the BigQuery Project Name field will automatically populate with the name of the GCP project in the JSON project key file.
Step 3.2.2: Select a Google Storage Location
Next, you’ll select the region used by your Google Cloud Storage (GCS) instance. This setting determines the region of the internal Google Storage Bucket Stitch uses during the replication process.
Using the Google Cloud Storage Location dropdown, select your GCS region. Refer to the Google BigQuery v2 reference for the list of regions this version of the Google BigQuery destination supports.
Note: Changing this setting will result in replication issues if data migration isn’t completed correctly.
Step 3.2.3: Define loading behavior
The last step is to define how Stitch will handle changes to existing records in your Google BigQuery destination:
-
Upsert: Existing rows will be updated with the most recent version of the record from the source. With this option, only the most recent version of a record will exist in Google BigQuery.
-
Append: Existing rows aren’t updated. Newer versions of existing records are added as new rows to the end of tables. With this option, many versions of the record will exist in Google BigQuery, capturing how a record changed over time.
Refer to the Understanding loading behavior guide for more info and examples.
Note: This setting may impact your Google BigQuery costs. Learn more.
Step 3.2.4: Save the destination
When finished, click Check and Save.
Stitch will perform a connection test to the Google BigQuery database; if successful, a Success! message will display at the top of the screen. Note: This test may take a few minutes to complete.
Step 4: Unpause your integrations
After you’ve successfully connected the new destination, un-pause your integrations. Your data will begin replicating according to the historical data option you previously selected.
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.