Product and documentation updates from the team at Stitch.
Stay up-to-date by subscribing to our RSS feed.
Intercom (v2): API upgrade to version 2.12
We’ve improved our Intercom (v2) integration to upgrade the API version to 2.12.
Shopify (v1): Update bookmark logic for transactions and order_refunds
We’ve improved our Shopify (v1) integration to update the bookmark logic for transactions and order_refunds.
Amazon S3 CSV (v1) update: Add credentials_cache_path property
We’ve improved our Amazon S3 CSV (v1) integration to add the credentials_cache_path property to define where the JSONFileCache is stored.
Pardot (v1) update: Requests library version upgrade
We’ve improved our Pardot (v1) integration by upgrading the requests library version to 2.32.3.
Shopify (v1) bug fix: Fix for GraphQL
We’ve improved our Shopify (v1) integration to fix the handling and logging errors for GraphQL.
Shopify (v1) update: Migration to GraphQL Streams
We’ve improved our Shopify (v1) integration to migrate to GraphQL Streams.
Square (v2) bug fix: 'list' object has no 'startswith' attribute
We’ve improved our Square (v2) integration to fix the issue: the list object has no startswith attribute.
Klaviyo (v1) update: API version upgrade to 2024-10-15
We’ve improved our Klaviyo (v1) integration to upgrade the API version to 2024-10-15.
Zuora (v1) update: Requests library version upgrade
We’ve improved our Zuora (v1) integration by upgrading the requests library version to 2.32.3.
Twilio (v1) update: Requests library version upgrade
We’ve improved our Twilio (v1) integration by upgrading the requests library version to 2.32.3.
Pipedrive (v1) update: Requests library version upgrade
We’ve improved our Pipedrive (v1) integration by upgrading the requests library version to 2.32.3.
Xero (v1) update: New fields in the schema of credit_notes
We’ve improved our Xero (v1) integration to add new fields to the credit_notes table:
- InvoiceAddresses
- Taxability
- TaxBreakdown
- SalesTaxCodeId
Square (v2): Roles stream removal
We’ve improved our Square (v2) integration to remove the deprecated roles stream.
Recurly (v1) update: Requests library version upgrade
We’ve improved our Recurly (v1) integration by upgrading the requests library version to 2.32.3.
Recharge (v2) bug fix: Multiple fixes
We’ve improved our Recharge (v2) integration by fixing the dependabot issue, pylint, and upgrading the requests library version to 2.32.3.
Zendesk Chat (v2) bug fix: Timezone issue
We’ve improved our Zendesk Support (v2) integration to fix the issue with the timezone.
Impact (v1) update: page_size increased
We’ve improved our Impact (v1) integration to increase the page_size to 20,000.
Deputy (v1) update: Requests library version upgrade
We’ve improved our Deputy (v1) integration by upgrading the requests library version to 2.32.3.
Zoom (v1) update: Ratelimit removal
We’ve improved our Zoom (v1) integration by removing the ratelimit dependency.
Slack (v1) update: pipefile.lock removal
We’ve improved our Slack (v1) integration by removing pipefile.lock.
GitHub (v2) update: New bookmark format
We’ve improved our GitHub (v2) integration by
updating the translate_state function to convert old bookmarks into the new bookmark format
{bookmarks {stream_name {repository ...}}}.
Facebook Ads (v1) upgrade: API to 21.0.5
We’ve improved our Facebook Ads (v1) integration by upgrading the API version to 21.0.5.
Zendesk Support (v2) update: aiohttp and requests library version upgrade
We’ve improved our Zendesk Support (v2) integration by upgrading aiohttp version to 3.11.11 and requests library version to 2.32.3.
Yotpo (v2) update: Requests library version upgrade
We’ve improved our Yotpo (v2) integration by upgrading the requests library version to 2.32.3.
Typeform (v2) update: Ratelimit removal
We’ve improved our Typeform (v2) integration by removing the ratelimit dependency.
Microsoft Advertising (v2) update: Stringcase removal
We’ve improved our Microsoft Advertising (v2) integration by removing the stringcase dependency.
Intercom (v2) update: Requests library version upgrade
We’ve improved our Intercom (v2) integration by upgrading the requests library version to 2.32.3.
ActiveCampaign (v1) update: Requests library version upgrade
We’ve improved our ActiveCampaign (v1) integration by upgrading the requests library version to 2.32.3.
MongoDB (v3) update: Pymongo version upgrade
We’ve improved our MongoDB (v3) integration by upgrading pymongo version to 4.10.1.
Heap (v1) improvement: Security enhancement for role assumption
We’ve improved our Heap (v1) integration by using a proxy AWS account for role assumption by using a two-step role assumption process.
Amazon DynamoDB (v1) improvement: Security enhancement for role assumption
We’ve improved our Amazon DynamoDB (v1) integration by using a proxy AWS account for role assumption and a two-step role assumption process.
Amazon S3 CSV (v1) improvement: Security enhancement for role assumption
We’ve improved our Amazon S3 CSV (v1) integration by using a proxy AWS account for role assumption by using a two-step role assumption process.
Google Analytics 4 (v1): Metrics and data incompatibility
We’ve improved our Google Analytics 4 (v1) integration to fix metrics and data incompatibility by implementing advertiserAdCostPerKeyEvent.
SFTP (v1): Deprecated terminaltables removal
We’ve improved our SFTP (v1) integration to remove the deprecated terminaltables dependency.
Amazon DynamoDB (v1): Deprecated terminaltables removal
We’ve improved our Amazon DynamoDB (v1) integration to remove the deprecated terminaltables dependency.
MongoDB (v3): Deprecated terminaltables removal
We’ve improved our MongoDB (v3) integration to remove the deprecated terminaltables dependency.
Klaviyo (v1) update: Requests library version upgrade
We’ve improved our Klaviyo (v1) integration by upgrading the requests library version to 2.32.3.
Impact (v1): Update for Actions and ActionUpdates
We’ve improved our Impact (v1) integration to forbid queries for Actions or ActionUpdates cannot have a StartDate exceeding 3 years in the past.
SendGrid Core (v1): ModuleNotFound error
We’ve improved our SendGrid Core (v1) integration to fix the ModuleNotFoundError: No module named 'pytz' error by adding pytz.
Google Analytics 360 (v1) bug fix: Compatibility
We’ve improved our Google Analytics 360 (v1) integration to fix the compatibility issue by upgrading the numpy version.
Zendesk Support (v2) bug fixes: Rate limit and retry for 5xx errors
We’ve improved our Zendesk Support (v2) integration to fix rate limit error. We’ve also added more retries to avoid the 5xx errors.
Dixa (v1) bug fix: Chunk length
We’ve improved our Dixa (v1) integration to fix the InvalidChunkLength error.
Amazon S3 CSV (v1) bug fix: Missing documents
We’ve improved our Amazon S3 CSV (v1) integration to fix the following issue:
CSV documents are missing, indicating a potential race condition. These documents were created or modified simultaneously with the extraction process, leading to a situation where the bookmark date advances, causing the documents to be missed during identification.
Zendesk Support (v2): Enhanced tap performance
We’ve updated our Zendesk Support (v2) integration to enhance the performance for large record counts.
Square (v2) bug fix: Removed invalid `singer-decimal` formats
We’ve updated our Square (v2) integration by removing the invalid singer-decimal formats from the locations schema.
Zendesk Chat (v1): Support for subdomain
We’ve updated our Zendesk Support (v1) integration to support subdomain.
HubSpot (v3): Support for new properties for deals stream
We’ve updated our HubSpot (v3) integration to support new properties for deals streams.
SFTP (v1) update: Support for multiple encoding formats
We’ve improved our SFTP (v1) integration to support any encoding format supported by Python 3.9.
Google Sheets (v3) update: Deprecated the file_metadata stream
We’ve updated our Google Sheets (v3) integration following the updates from Google on the Oauth scopes.
ActiveCampaign (v1): Updated the bounce_logs schema
We’ve updated our ActiveCampaign (v1) integration to allow the code field as string.
Hubspot integration: New version (v3) now available!
A new version (v3) of the Hubspot integration is now available!
Changes in this version include:
- Upgrading
ownersAPI endpoint from v2 to v3. - Updating the primary key in the
ownerstable fromownerIdtoid. - Schema modifications to align with the Hubspot API.
Full details can be found on the pull request against the open sourced integration here.
Klaviyo (v1) update: API upgrade
We’ve updated the integration’s API version.
The base URL has been updated for all streams.
The API key authorization has been moved from the query parameters to the request headers.
The schema for all streams has been updated to include all relevant fields.
New tables have been added: subscribed_to_email and subscribed_to_sms.
MongoDB (v3) update: String projection
We’ve improved our MongoDB (v3) integration to allow the specification of a string projection, instead of using only integer values.
For example, the following sample projection now works:
{"name": "$personName"}
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions to avoid the following error:
Error: 400 Cannot have filter_partition dimension without specifying filter-partitions in the request.
Mambu (v4) bug fix: Date windowing pagination use
We’ve updated our Mambu (v4) integration to fix issues during the integration execution:
- Out-Of-Memory Issue: Initially, all records from the start date to the current date were pulled, and the integration allowed generator buffers to grow without limit, surpassing the default extraction memory limits rapidly. To address this, we implemented date windowing (default size = 1 day) and pagination for multi-threaded streams, a limited generator buffer growth to finite boundaries and we eliminated performance metrics to reduce performance overheads.
- Execution Time: Previously, to address performance concerns, a single-threaded implementation was adopted, resulting in slow extraction speeds. Multi-threaded execution has been reintroduced to expedite historical sync execution with a maximum thread count equal to 20.
- Data Discrepancy:
Data discrepancies were reported in certain streams after the extraction gets interrupted due to extraction timeout and memory issue.
The bookmark strategy has been revised for multi-threaded generators to address data discrepancies.
We segregated the
LoanAccountssub-stream bookmarking to rectify data inconsistencies.
Intercom (v2) update: New fields
We’ve updated our Intercom (v2) integration to add some new fields in the companies and the contacts stream.
Intercom (v2) bug fix: Conversations stream bookmarking
We’ve updated our Intercom (v2) integration to fix the following issue during the integration execution.
The conversations records have been updated after the previous synchronization start was missed. This issue has been fixed by bookmarking the last synchronization start time.
A long running synchronization was stuck in loop after interruption because the synchronization was resumed from the start. Nested filters have been added in search_query to resume the synchronization from the last processed conversations record.
Intercom (v2) bug fix: Conversations schema update
We’ve updated our Intercom (v2) integration to fix the following error during the integration execution.
The assignee object was not getting populated as a response using the API version 2.5. The conversations schema has been updated.
Chargebee (v1) update: New field in subscriptions schema
We’ve updated our Chargebee (v1) integration to add the discount field to the subscriptions schema.
LinkedIn Ads (v2) update: API upgrade and new fields
We’ve updated the LinkedIn Ads integration’s API version from 2023-04 to 2024-03.
We’ve updated API endpoints for the following streams: campaign_groups, campaigns, creatives.
A cursor-based pagination has been implemented for the following streams: accounts, campaign_groups, campaigns, creatives.
Unsupported pivot and pivotValue have been removed from the fields query parameters in Analytics API requests.
New fields have been added to the video_ads stream. It now requires the scope r_organization_social to synchronize the records.
Data is not available for change_audit_stamps in the new endpoint.
Facebook Ads (v1) bug fix: Summary param error
We’ve updated our Facebook Ads (v1) integration to fix the following error:
Status: 400
Response:
{
"error": {
"message": "(#100) Cannot include cost_per_inline_post_engagement, unique_inline_link_click_ctr, frequency, video_play_curve_actions, unique_ctr, ctr, spend, unique_clicks, unique_inline_link_clicks, video_p100_watched_actions, campaign_name in summary param because they weren't there while creating the report run. All available values are: ",
"type": "OAuthException",
"code": 100,
"fbtrace_id": "*************"
}
}
While awaiting for Facebook’s fix, a workaround is now available. A new retry logic has been implemented, you can now retry the request for a successful data retrieval.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Google Analytics (v1) bug fix: New supported data type
We’ve updated our Google Analytics 4 (v1) integration to fix an issue with the API. The NUMBER data type is now supported in the catalog for metric fields that are originally specified as INTEGER types in the Google Analytics 4 API.
Salesforce (v2) bug fix: Pk chunking condition fix
We’ve updated our (v) integration to fix the following error during the integration execution:
CRITICAL One or more batches failed during PK chunked job.
Google Sheets integration: New version (v3) now available!
A new version (v3) of our Google Sheets integration is now available!
The date datatype support has also been removed.
GitHub (v2) fix: remove uri format from the events url field
We’ve updated our GitHub (v2) integration to fix the following error:
INFO Exit status is: Discovery succeeded. Tap failed with code -15. Target failed with code 1 and error message: "Error persisting data to Stitch: 400: {'error': 'Record 0 for table events did not conform to schema:\n#: #: no subschema matched out of the total 2 subschemas\n#/payload}".
The URI format restriction for the events field has been removed.
Facebook Ads (v1) update: SDK version upgrade
We’ve upgraded our Facebook Ads (v1) integration’s Facebook SDK version to 19.0.0.
Shopify (v1) update: API version upgrade and schema changes
We’ve upgraded our Shopify (v1) integration’s Shopify SDK version to 12.4.0.
We’ve updated the Shopify integration’s API version from 2023-04 to 2024-01.
We’ve removed the currency, accepts_marketing, accepts_marketing_updated_at, and marketing_opt_in_level fields from the abandoned_checkout and customers tables.
New poNumber and taxExempt objects have been added to the orders table.
Mambu (v4) update: Update table to full table
We’ve improved our Mambu (v4) integration. Our clients table’s replication method has been changed from key-based incremental to full table.
MongoDB (v3) update: MongoDB server not supporting sessions
We’ve improved our MongoDB (v3) integration to handle the MongoDB server when its not supporting sessions. It will now revert to the prior behavior without using a session and without sending a keepalive message.
Amazon S3 CSV (v1) bug fix: Missing type information in JSON schema
We’ve updated our Amazon S3 CSV (v1) integration to fix the following error during the data loading process:
ERROR Target exited abnormally with status 1. Terminating tap.
INFO No tunnel subprocess to tear down
INFO Exit status is: Discovery succeeded. Tap succeeded. Target failed with
code 1 and error message: "Error persisting data to Stitch: 400: {'error': 'Invalid JSON schema: key null: expected type is one of JSONObject, found: String'}".
Recharge (v2) update: API call performances improvement
We’ve updated our Recharge (v2) integration to optmize API call performances.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Mambu (v4) update: None value support in list
We’ve updated our Mambu (v4) integration to support the None value in the users.access.permissions list. Null values are allowed in the list.
Hubspot (v2) bug fix: Retrieval of contacts to company
We’ve updated our HubSpot (v2) integration to fix an issue when retrieving contacts_by_company per company_id with a large number of company IDs.
Mambu (v4) update: None value support
We’ve improved our Mambu (v4) integration by adding the None value support in HashableDict. A None value is now added at the end of a list before the list is hashed.
MongoDB (v3) bug fix: Session timeout
We’ve updated our MongoDB (v3) integration to fix an issue with the session timeout. The session is now refreshed every ten minutes during oplog queries.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Asana (v2) update: New subtasks table
We’ve updated our Asana (v2) integration to add a new subtasks table.
Recharge (v2) update: Retry for ChunkedEncodingError
We’ve improved how our Recharge (v2) integration handles errors. The integration will now retry when a ChunkedEncodingError is encountered.
SurveyMonkey (v2) bug fix: heading field in simplified_responses stream
We’ve updated our SurveyMonkey (v2) integration to fix the missing heading field issue in the simplified_responses stream.
Google Ads (v1) update: API version upgrade
We’ve updated the Google Ads (v1) integration’s API version to 15.
HubSpot (v2): Custom objects support
We’ve updated our HubSpot (v2) integration to add support for custom objects. You will now be able to replicate a table for each custom object in our HubSpot account.
The custom object tables support both standard and custom properties, and also support associations with emails, meetings, notes, tasks, calls, conversations, contacts, companies, deals, and tickets.
If you already have a HubSpot connection, you will need to re-authorize it to be able to select the new tables.
Front integration: New version (v2) now available!
A new version (v2) of our Front integration is now available!
We’ve implemented the new Front Analytics API and made changes in all streams.
Snapchat Ads (v1) bug fix: Datetime conversion issue
We’ve updated our Snapchat Ads (v1) integration to fix issues related to Daylight Savings Time when converting a datetime to midnight in the local time.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Intercom (v2) bug fix: Add retry logic for JSON decode errors
We’ve fixed an issue in our Intercom (v2) integration by adding a a response doesn’t return any JSON content.
Chargebee (v1) bug fix: Update tax_rate field type
We’ve fixed a data type issue in our Chargebee (v1) integration to avoid truncating the value of the tax_rate field.
Chargebee (v1) update: Add missing customer details
We’ve updated our Chargebee (v1) integration to add the business_entity_id, cf_people_id, and tax_providers_fields fields to the customers stream.
Outreach (v1): Fix issue with attribute
We’ve updated our Outreach (v1) integration to fix an issue related to an attribute in the mailings stream.
MongoDB (v3) bug fix: SSL issue
We’ve updated our MongoDB (v3) integration to fix an issue with connection parameters when using SSL.
SurveyMonkey integration: New version (v2) now available!
A new version (v2) of our SurveyMonkey integration is now available!
We’ve added a new surveys stream.
Outreach (v1) update: Leaving beta!
Our Outreach integration has left open beta and is now generally available! Check out the documentation for more info about this integration.
Looker (v1) update: API version upgrade
We’ve updated the Looker integration’s API version to 4.0.
Amazon S3 CSV (v1) update: JSONL support
We’ve updated our Amazon S3 CSV (v1) integration to introduce support for JSONL files.
Marketo (v2) bug fix: Max API calls issue
We’ve fixed an issue related to the Max Daily API Calls parameter in our Marketo (v2) integration.
Google Analytics 4 (v1) update: Leaving beta!
Our Google Analytics 4 integration has left open beta and is now generally available! Check out the documentation for more info about this integration.
Kustomer (v1) update: New fields
We’ve updated our Kustomer (v1) integration to add some new fields in the conversations stream.
Facebook Ads (v1) update: Add retry logic for status code 503
We’ve improved our Facebook Ads (v1) integration by adding a retry logic system when an error with the HTTP status code 503 (Service Unavailable) occurs.
GitHub (v2) update: `files` and `stats` fields from commit-related schemas
We’ve updated our GitHub (v2) integration to remove the files and stats fields from the commits and pr-commits streams, since these are not returned by the GitHub API.
Outreach (v1) update: Request timeout
We’ve improved our Outreach (v1) integration by adding a request timeout option with a default value of 300 seconds.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Stripe integration: New version (v3) now available!
A new version (v3) of our Stripe integration is now available!
We’ve upgraded the Stripe API version to 2022-11-15 and made some schema updates.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Facebook Ads (v1): Add conversions to insights streams
We’ve updated our Facebook Ads (v1) integration to add the conversions and conversion_values fields to insights streams.
Salesforce integration: New version (v2) now available!
A new version (v2) of our Salesforce integration is now available!
We’ve updated the LightningUriEvent stream to use the EventIdentifier field as the Primary Key.
Intaact (v1) update: Match more input filenames
We’ve updated our (v) integration to find any input file whose name starts with table_name and ends with .csv.
Google Analytics 4 (v1) bug fix: Field updates for e-commerce reports
We’ve fixed broken e-commerce reports in our Google Analytics 4 (v1) integration by updating incompatible fields.
Square (v2) update: New payouts stream
We’ve updated our Square (v2) integration to replace the deprecated settlements stream with the payouts stream.
TikTok Ads integration: New version (v1) now available!
A new version (v1) of our TikTok Ads integration is now available!
We’ve upgraded the TikTok Ads API version, made some updates to existing schemas, and introduced a new feature to fetch deleted records.
Pendo (v1) bug fix: Set maximum record limit
We’ve fixed an issue in our Pendo (v1) integration by resetting the record limit in case of a race condition.
Mixpanel (v1) bug fix: Add retries for ChunkedEncodingError
We’ve fixed an issue in our Mixpanel (v1) integration by adding retries in case a ChunkedEncodingError error occurs.
Pendo (v1) update: Primary Key changes
We’ve updated Primary Keys in several streams of our Pendo (v1) integration.
Pendo (v1) update: Multiple apps support
We’ve updated our Pendo (v1) integration to introduce support for multiple apps.
MongoDB integration: New version (v3) now available!
A new version (v3) of our MongoDB integration is now available!
We’ve upgraded the database integration’s PyMongo version to 4.4.0! This version supports MongoDB 3.6, 4.0, 4.2, 4.4, 5.0, 6.0, and 7.0.
Pendo (v1) update: Leaving beta!
Our Pendo integration has left open beta and is now generally available! Check out the documentation for more info about this integration.
Square integration: New version (v2) now available!
A new version (v2) of our Square integration is now available!
We’ve upgraded the Square API version, made some updates to existing schemas, and replaced the deprecated employees stream with the team_members stream.
Shopify (v1) bug fix: Add retries for 404 error
We’ve fixed an issue in our Shopify (v1) integration by adding retries in case a 404 error occurs.
MailChimp (v1) bug fix: Update email_activity_date_window validation
We’ve fixed an issue in our MailChimp (v1) integration to better handle None values for the email_activity_date_window property.
Chargify (v1) bug fix: Update subscriptions schema
We’ve updated the subscriptions schema in our Chargify (v1) integration to fix the data type for the portal_invite_last_accepted_at field.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Custom notifications in Standard Plan
The custom notifications feature is now available for all plans, including Standard Plan.
TikTok Ads (v0) bug fix: Sync records from start date
We’ve fixed an issue in our (v) integration to ensure that Stitch uses the start date specified in the configuration when syncing records.
Shopify (v1) bug fix: Backoff for ConnectionResetError
We’ve fixed an issue in our Shopify (v1) integration by adding a backoff in case a ConnectionResetError occurs.
Zendesk Support (v2) update: New streams
We’ve updated our Zendesk Support (v2) integration to add two new streams: talk_phone_numbers and ticket_metrics_event.
TikTok Ads (v0) bug fix: Backoff for errors
We’ve fixed an issue in our (v) integration by adding a backoff in case an error with one of the following codes occurs: 40200, 40201, 40202, 40700, and 50002.
MailChimp (v1) update: New property for reports_email_activity stream
We’ve updated our (v) integration to add a new date_window property in the reports_email_activity stream.
Pipedrive (v1) bug fix: Backoff for errors
We’ve fixed an issue in our Pipedrive (v1) integration by adding a backoff in case 5XX errors occur.
Zendesk Support (v2) bug fix: Backoff for errors
We’ve fixed an issue in our Zendesk Support (v2) integration by adding a backoff in case ProtocolError or ChunkedEncodingError errors occur.
Typeform (v2) update: New property in submitted_landings stream
We’ve updated our Typeform (v2) integration to add the tags property in the submitted_landings stream.
Zendesk Support (v1) bug fix: Infinite Loop for users stream
We’ve fixed an issue in our Zendesk Support (v1) integration which was causing infinite loops in the users stream.
Zendesk Support (v1) update: Increase sync limit for users stream
We’ve updated our Zendesk Support (v1) integration to used the incremental export API for the users stream, which allows Stitch to sync more than 1000 records per query.
Mixpanel (v1) update: New Export Events parameter
We’ve updated our Mixpanel (v1) integration to add a new Export Events parameter that allows you to filter data on specific event names.
Shopify (v1) bug fix: Backoff for IncompleteRead error
We’ve fixed an issue in our Shopify (v1) integration by adding a backoff in case an IncompleteRead error occurs.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Impact (v1) bug fix: Handle empty model_id
We’ve changed the way our Impact (v1) integration handles the absence of value for the model_id field to avoid errors.
Impact (v1) bug fix: Error after editing connection
We’ve fixed an issue in our Impact (v1) integration that set the model_id field to None after the connection was edited.
Shopify (v1) bug fix: Bookmarking strategy fix
We’ve changed the way our Shopify (v1) integration bookmarks streams to avoid issues when a sync is interrupted.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
GitHub (v2) bug fix: Handle empty repositories
We’ve updated our GitHub (v2) integration to allow the sync to continue when it encounters an empty repository.
Google Ads (v1) update: Bump API to v13
We’ve updated the Google Ads (v1) integration API version to Google Ads API (v13).
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Typeform (v2) update: Handle missing form ID and form questions
We’ve updated our Typeform (v2) integration to:
- Sync data for all forms if no form ID is provided.
- Continue syncing data instead of failing when a form doesn’t contain any questions.
HubSpot (v2) bug fix: Bookmarking strategy fix
We’ve changed the way our HubSpot (v2) integration bookmarks streams to avoid issues with records updated during a sync.
Pipedrive (v1): New stream
We’ve updated our Pipedrive (v1) integration to add a new deal_fields stream.
LinkedIn Ads (v2) update: API upgrade
We’ve updated the LinkedIn Ads integration’s API version fom 202207 to 202302.
Google Search Console (v1) update: New search types
We’ve updated our Google Search Console (v1) integration to add support for three new search types: news, googleNews, and discover.
Pendo (v1) bug fix: Type error in the accounts stream
We’ve fixed an issue related to replication keys in our Pendo (v1) integration.
Google Search COnsole (v0) bug fix: Handle no data exception for sitemaps stream
We’ve fixed an issue related to sitemaps streams with no data in our (v) integration.
Amazon DynamoDB (v1) bug fix: Fix error handling for incorrectly set-up log based streams
We’ve fixed an issue in the set up for log-based streams in our Amazon DynamoDB (v1) integration.
Marketo (v2): New field available
The campaignId field is now available for the activities stream in our Marketo (v2) integration.
Pendo (v1) bug fix: Visitor history issue
We’ve fixed an issue with the visitor_history stream in our Pendo (v1) integration. Records older than the bookmark are no longer synchronized.
LinkedIn (v2): Allow processing of large number of accounts
We’ve improved our LinkedIn Ads (v2) integration to avoid errors when working with a large number of accounts.
ActiveCampaign (v1): New field
We’ve updated our ActiveCampaign (v1) integration to add a phone field in he contacts stream.
ActiveCampaign (v1): Field type update
We’ve updated our ActiveCampaign (v1) integration to support the string type for the style.button.padding field in the forms stream.
Twilio (v1): New stream, fields, and bug fixes
We’ve updated our Twilio (v1) integration to fix some issues, add new fields in several streams and add a new account_balance stream.
Yotpo (v2): Synchronize deleted reviews
We’ve fixed an issue related to the reviews stream in our Yotpo (v2) integration. The stream will now synchronize deleted reviews.
New integration: Iterable
A new Iterable integration is now available in beta!
Get started by creating a new Iterable integration or learning more in our documentation.
Pipedrive (v1) improvement: Improved retry logic for null requests for DealsFlow stream
We’ve added retry logic to the Pipedrive (v1) dealsflow stream. This allows the integration to automatically retry API requests when it returns a status of 200 but a null body.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Amazon DynamoDB (v1) update: Handle empty projections
We’ve updated our Amazon DynamoDB (v1) integration to properly handle empty projections.
Campaign Manager (v1) update: Handle queued status
We’ve updated our Campaign Manager (v1) integration to explicitely handle the QUEUED file status.
New version (v4) of Mambu integration
A new version (v4) of our Mambu integration is now available!
Learn more about the integration and these features in our Mambu integration documentation.
Google Ads (v1) update: Bump API to v12
We’ve updated the Google Ads (v1) integration API version to Google Ads API (v12).
Campaign Manager update: API v4 version bump
We’ve updated the Campaign Manager (v1) integration API version to Campaign Manager API (v4).
HubSpot (v2) update: New tickets stream
A new tickets stream has been added to our HubSpot (v2) integration.
To use this stream, you will need to re-authorize the existing connection.
Help Scout (v1): New streams
Three new streams have been added to our Help Scout (v1) integration:
teamsteam_usershappiness_ratings
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
New integration: Snapchat Ads
A new Snapchat Ads integration is now available!
Get started by creating a new Snapchat Ads integration or learning more in our documentation.
New integration: TikTok Ads
A new TikTok Ads integration is now available!
Get started by creating a new TikTok Ads integration or learning more in our documentation.
Zuora (v1): Ignore unsupported related objects
We’ve fixed a bug with related objects in our Zuora (v1) integration. Fields that cause issues when added as related objects will now be ignored.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Pendo (v1): Skip `Do Not Process` visitor records
Pendo stops collecting events from visitors with the donotprocess flag, so we’ve updated our Pendo (v1) integration to skp those records during replication.
Remove `order` query param from manual_journals request
The Xero API currently has a bug where all manual_journal records created or modified since the last bookmark are returned instead of 100 per page causing, in some instances, API quotas to be exceeded.
Xero support noticed this only happens when order is added as a query parameter in the request. This temporary fix removes the order query parameter when retrieving data for the manual_journals stream until Xero fixes the bug. Data will still be retrieved in it’s expected for the Xero (v1) integration.
Shopify (v1) update: API version upgrade and schema changes
We’ve upgraded our Shopify (v1) integration’s ShopifyAPI and SDK version to 12.0.1.
We’ve removed the last_order_id, last_order_name, orders_count, and total_spent fields from the customer object in the orders table.
A new email_marketing_consent object has been added to the customers and orders tables.
Microsoft SQL Server (v1): Log4j update
We’ve updated the Log4j version in our Microsoft SQL Server (v1) integration due to the vulnerability in CVE-2020-9493.
Google Analytics 4 (v1) update: New field exclusions
We’ve updated our Google Analytics 4 (v1) integration to add new field exclusions after a change in the Google Analytics 4 API.
Google Analytics 4 (v1): new reports
We’ve added two new premade reports with dimension filters to our Google Analytics 4 (v1) integration: conversions_report and in_app_purchases.
Amazon DynamoDB (v1) update: Reduce logging frequency
We’ve improved our Amazon DynamoDB (v1) integration to reduce the amount of logs produced during replication by logging only at the start of a full-table scan.
Shopify (v1) update: Canonicalize transactions in OrderRefunds
We’ve improved our Shopify (v1) integration to handle transactions containing keys with the same name but with a different case. For example: token and Token. An error will occur only if both keys are present and have different values.
Google Analytics 4 update: bad metrics marked unsupported
We’ve updated our (v) integration to filter bad metric names so a connection can successfully complete a check. The bad metrics will be marked unsupported in field selection.
Zendesk Chat (v1) update: API fixes and new fields
We’ve improved our Zendesk Chat (v1) integration by adding fields in the shortcuts and bans streams and fixing some API issues.
Typeform (v2): Support submitted landings without answers
We’ve fixed an issue in our Typeform (v2) integration causing the data extraction to fail when at least one submitted landing had no answer. The integration will now check if a stream’s child key is blank before trying to process its children.
New User Role: General User
In an effort to increase account security, we have introduced a new user role: General User. This makes it possible for you to separate users who handle account administration from those who are in the app to manage the Stitch pipeline. A General User can manage sources and destinations but cannot take any action tied to billing or accessing the Stitch account. Check out our team member roles & permissions page to learn more about the General User role.
Facebook Ads (v1) update: Updated API version
We’ve bumped our Facebook Ads (v1) API version up to 14.
Mambu (v2) update: Time zone endpoint version downgrade
We’ve improved our Mambu (v2) integration by downgrading the version of the API endpoint used to retrieve the client time zone. This was done to remove the extra steps needed to use the more recent version.
Typeform integration: New version (v2) now available!
A new version (v2) of our Typeform integration is now available!
We’ve improved the Typeform integration by adding a new table and some new fields.
GitHub integration: New version (v2) now available!
A new version (v2) of our GitHub integration is now available!
We’ve improved the GitHub integration by adding some new fields, as well as support for custom URLs.
Trello (v1) update: Added configurable parameter to cards table
We’ve added the configurable parameter cards_respoonse_file to the cards table of our Trello integration. The default value is 1000.
Mambu (v2) improvement: Timezone improvement
We’ve improved our Mambu date-time fields to eliminate several timezone related issues:
- All
date-timedata has been converted to UTC for processing - Implemented functionality to get the tenant’s timezone so that calculations for the local time are done using the tenant’s, and not the local computer’s
- The following streams now use
date-timeinstead of justdate:clients,communications,deposit_transactions,loan_accounts,loan_transactions
Recharge (v2) update: Cleanup customer table
We’ve removed the shopify_customer_id field which was removed by Recharge in favor of the external_customer_id object.
LinkedIn Ads (v1) update: Check existing access tokens
We’ve improved our LinkedIn Ads (v1) integration to avoid generating a new access token when a valid one already exists. The integration now checks the expiration date of an existing token and uses it if it is valid, instead of creating a new one.
Stripe (v2) update: Reduce API calls
We’ve improved our Stripe (v2) integration to reduce the amount of calls made to the Stripe API. The integration now extracts data from the last 7 days by default. This date range is configurable and can be set to a maximum of 30 days.
Yotpo integration: New version (v2) now available!
A new version (v2) of our Yotpo integration is now available!
We’ve improved the Yotpo integration by updating our tables and fields. See the updates by visiting our documentation!
HubSpot (v2) update: Replication key automatically included
We’ve updated the deals table of our HubSpot integration by changing its replication method to INCREMENTAL and updating the replication key to property_hs_lastmodifieddate.
Mambu (v2) improvement: Changed `deposit_accounts` sorting field
We’ve changed the sorting field from id to lastModifiedDate for the deposit_accounts table in our Mambu integration. The MultithreadedBookmarkGenerator changes the filter at every n records so switching to the lastModifiedDate ensures that we don’t miss older records during the extraction process.
Pendo (v1) update: Set default Include Anonymous Visitors value
We’ve improved our Pendo (v1) integration by setting a default false value for the Include Anonymous Visitors parameter.
Close.io (v1) update: Ignore future-dated bookmark values
We’ve improved our Close.io (v1) integration to avoid writing future-dated activities records.
Pipedrive (v1) bug fix: Transformation and type issues
We’ve fixed issues related to transformations and NoneType objects in our Pipedrive (v1) integration.
Google Sheets integration: New version (v2) now available!
A new version (v2) of our Google Sheets integration is now available!
We’ve improved the Google Sheets integration by enhancing data type discovery and adding support for shared drives. See the updates by visiting our documentation!
Recharge integration: New version (v2) now available!
A new version (v2) of our Recharge integration is now available!
We’ve improved the Recharge integration by updating our tables and fields. See the updates by visiting our documentation!
Codat (v1) update: Update key for company stream
We’ve improved our Codat (v1) integration by updating the key companies with results in the company stream after an update in the Codat API.
Pipedrive (v1) update: Handle new structure for users stream
We’ve improved our Pipedrive (v1) integration to support a structure change in the Users API. Stitch now accepts both single elements and JSON objects in the response.
Dixa (v1) update: Extend the `activity_logs` schema
We’ve improved our Dixa (v1) integration by adding some missing fields in the activity_logs stream.
Twitter Ads (v1) bug fix: Resolve ConnectionError
We’ve fixed a bug in our Twitter Ads (v1) integration causing an error when replicating streams with a large number of records, such as the targeting_conversations and targeting_location streams.
New integration: Dixa
A new Dixa integration is now available!
Get started by creating a new Dixa integration or learning more in our documentation.
Stripe integration: New version (v2) now available!
A new version (v2) of our Stripe integration is now available!
We’ve improved the Stripe integration adding a new table and parameter. Here’s a look at what has changed:
- New parameter:
lookback_window. The number of historical days’ worth of data to replicate from thestart_datevalue for each replication job for your streams. The maximum lookback window is600days. - New table:
payment_intents. This table contains information about payments, from creation through checkout, in your Stripe account.
New feature: New Upgraded Plans!
Stitch has brand new upgraded plans!
Check out the new guide for more information.
Workday RaaS (v1) bug fix: Fixed issue with boolean values
We’ve fixed a bug in our Workday RaaS (v1) integration causing false positives when evaluating 0 and 1 as boolean values.
Google Ads (v1) update: Add limit clause to core table queries
We’ve added support for configurable page limits for all core tables except: call_details, campaign_labels, ad_group_criterion, and campaign_criterion.
MongoDB (v2): PyMongo upgrade
We’ve upgraded our Google Ads (v1) database integration’s PyMongo version to 3.12.3! This version supports Google Ads 2.6, 3.0, 3.2, 3.4, 3.6, 4.0, 4.2, 4.4, and 5.0.
Google Ads (v1) update: Add request timeout to gas.search
We’ve improved our Google Ads (v1) integration to add a request timeout option to the search request with a default value of 900 seconds.
Yotpo (v1) update: Products table endpoint changes
Yotpo recently change the endpoint for the products schema and the category attribute has been deprecated. Since it cannot be deleted, we’ve updated our category.name and category.id attributes to accept null values.
LinkedIn Ads (v1) update: Access token configurations
You can now provide an access token for existing connections and generate new access tokens for new connections using refresh tokens in our LinkedIn Ads (v1) integration.
Facebook Ads (v1) update: Updated API version
We’ve bumped our Facebook Ads (v1) API version up to 13.
Yotpo (v1) improvement: Handling response with 500 status code
We’ve improved how our Yotpo (v1) integration handles errors by adding an excption for status code 500, and an expection class of 500 for backoff.
JIRA (v2) update: Provide description of groups in README
We’ve added a description and some sample values for groups in our Singer README file.
JIRA (v2) update: Date format transformation
This update converts the userStartDate and userReleaseDate fields in our JIRA (v2) to yyyy-mm-dd format before transformation.
Typeform (v1) update: Update table to incremental
Our landings table’s replication method has been changed from full table to key-based incremental.
Google Ads (v1) update: New tables!
We’ve added a lot of new tables to our Google Ads (v1) integration catalog. See the list below for the new tables:
ad_group_criterioncampaign_criterioncarrier_constantfeedfeed_itemlanguage_constantmobile_app_category_constantmobile_device_constantoperating_system_version_constanttopic_constantuser_interestuser_list
Google Ads (v1) improvement: Implement Automatic Keys
We noticed dupilicate results being written for distinct reporting records across our Google Ads (v1) integration reporting tables. This caused some overwritting on records that should not have been overwritten.
To fix this we’ve implemented automatic keys to ensure that data can be loaded and identified downstream as distinct records.
Close.io (v1) update: Updated window size
We’ve added a date window to the activities table in our Close.io (v1) integration. The default window size is 15 days.
Shopify (v1) bug fix: Fixed mismatched schema transformation error
For fields that are not originally found in the Shopify schema catalog, it will be removed and added to the patternProperties object attribute to acknowledge that it was an extra field.
Pendo (v1) improvement: Integer types received as string value
This Pendo (v1) integration update receives integer attributes from Pendo as string values with decimals. This will allow custom metadata types to be more permissive.
Zendesk Chat (v1) update: New table
We’ve added the chat_webpath_array table to our Zendesk Chat (v1) integration to validate the array type attributes in our tables.
Pendo (v1) update: Support for EU endpoints
We now include support for EU enpoints for our Pendo (v1) integration!
Google Ads update: New labels table
We’ve added the labels table to our Google Ads (v1) integration. Additionally, we’ve added the campaign.labels attribute to all reports that contain the campaigns resource.
Google Ads (v1) update: Table updates
We’ve updated some of our Google Ads (v1) tables:
- Removed
campaign_idfromcampaign_budgets - Added
call_detailstables
Mambu (v2) update: Continued refactoring and new fields
We’ve made many updates to our Mambu (v2) integration. See the list below for changes:
- Refactoring of the
credit_arrangementsstream - Refactoring of the
usersstream - Refactoring of the
activitiesstream - Refactoring of the
audit_trailstream - Added the
interest_accrual_breakdownstream - Added new fields to the
tasksstream - Added new fields to the
loan_transactionsstream
Mambu (v2) update: Refactored seven streams
We’ve refactored seven more of our Mambu (v2) integration streams. See the list below for the streams:
communicationsdeposit_transactionsgroupsindex_rate_sourcesinstallmentsloan_transactionstasks
Mambu (v2) update: Continued refactoring, new fields added
We’ve made many updates to our Mambu (v2) integration. See the list below for changes:
- Refactored
centres,clientsandbranchesstreams - Added
assignedBranchKeyfield toclientsstream
Activecampaign (v1) bug fix: Fixed teh forms stream array error
We’ve added the string type to the recent field in the forms stream to stop a recurring error.
Mambu (v2) update: Misc bug fixes and feature updates
We’ve made many updates to our Mambu (v2) integration. See the list below for changes:
- added
currencyfield toloan_accounts - added
payment_detailsfield todeposit_transactions - added
statusfield totasksstream - added sorting to
gl_journal_entriesstream - fixed
loan_accountsbeing skipped if updated while the extraction is running - refactored
deposit_accountsandcardsstreams
Github (v1) update: Fix team_members stream primary key
We’ve updated the team_members stream’s primary keys to: id, team_slug.
Stripe (v1) update: Change events stream date window
Previously the date window for our Stripe (v1) integration was one week, which caused some connections with many events’ bookmarks to never update.
We’ve updated this window to one day to allow all events to make it through the date window.
JIRA (v2) update: Add request timeout
We’ve improved our JIRA (v2) integration to add a request timeout option with a default value of 300 seconds.
Mambu (v2) bug fix: Fixed missing records
Sorting has been added to the Journals endpoint to ensure no records are missed during extraction.
New feature: Support for SSO with Google Workspace
We’ve expanded our list of supported Identity Providers to include Google Workspace!
Using a generic SAML 2.0 app, you can now configure Stitch to use SSO with your Google Workspace instance. Check out the new step-by-step guide for help getting set up.
Microsoft Advertising (v2) update: Prefer Microsoft Identity Platform Authentication
To modernize the methods of authentication for our Microsoft Advertising (v2) integration, we’ve updated our feature detection to prefer Microsoft Identity Platform as the default.
Mambu (v2) update: New field in the loan_accounts stream
We’ve updated our Mambu (v2) integration to add an last_account_appraisal_date field to the loan_accounts stream.
Xero (v1) improvement: Change endpoint to check access against
To minimize the size of potential responses for our Xero (v1 integration, we’ve updated the check_platform_acces function to use the Currencies endpoint.
Google CloudSQL MySQL integration: New version (v2) now in beta
A new version (v2) of our Amazon Aurora MySQL RDS integration is now in beta!
This version (v2) of Stitch’s Amazon Aurora MySQL RDS integration optimizes replication by utilizing Avro schemas to write and validate data, thereby reducing the amount of time spent on data extraction and preparation. Compared to previous versions of the Amazon Aurora MySQL RDS integration, this version boasts increased performance and overall reduced replication time.
Notable improvements and changes in this version also include:
- New column (field) naming rules. Avro has specific rules that dictate how columns can be named. As a result, column names will be canonicalized to adhere to Avro rules and persisted to your destination using the Avro-friendly name. Refer to the Column name transformations section in the Amazon Aurora MySQL RDS docs for more info.
- Expanded data type support. This version supports additional Amazon Aurora MySQL RDS data types. Refer to the Amazon Aurora MySQL RDS data types documentation for more info.
Note: The following features aren’t currently supported, but will be before the integration leaves beta:
- Custom SSL certificates and certificate authorities
To get a look at how this version compares to the previous version of Amazon Aurora MySQL RDS, refer to the Amazon Aurora MySQL RDS version comparison documentation.
Amazon Aurora MySQL RDS integration: New version (v2) now in beta
A new version (v2) of our Amazon Aurora MySQL RDS integration is now in beta!
This version (v2) of Stitch’s Amazon Aurora MySQL RDS integration optimizes replication by utilizing Avro schemas to write and validate data, thereby reducing the amount of time spent on data extraction and preparation. Compared to previous versions of the Amazon Aurora MySQL RDS integration, this version boasts increased performance and overall reduced replication time.
Notable improvements and changes in this version also include:
- New column (field) naming rules. Avro has specific rules that dictate how columns can be named. As a result, column names will be canonicalized to adhere to Avro rules and persisted to your destination using the Avro-friendly name. Refer to the Column name transformations section in the Amazon Aurora MySQL RDS docs for more info.
- Expanded data type support. This version supports additional Amazon Aurora MySQL RDS data types. Refer to the Amazon Aurora MySQL RDS data types documentation for more info.
Note: The following features aren’t currently supported, but will be before the integration leaves beta:
- Custom SSL certificates and certificate authorities
To get a look at how this version compares to the previous version of Amazon Aurora MySQL RDS, refer to the Amazon Aurora MySQL RDS version comparison documentation.
Shopify (v1) update: Request timeout
We’ve improved our Shopify (v1) integration to add a request timeout option with a default value of 300 seconds.
SFTP (v1) update: Request timeout
We’ve improved our SFTP (v1) integration to add a request timeout option with a default value of 300 seconds.
MariaDB integration: New version (v2) now in beta
A new version (v2) of our MariaDB integration is now in beta!
To get a look at how this version compares to the previous version of MariaDB, refer to the MariaDB version comparison documentation.
Pendo (v1) update: Configurable date window
We’ve improved our Pendo (v1) integration by adding a date window with a configurable size to the Events stream.
LinkedIn Ads (v1) update: Request timeout
We’ve improved our LinkedIn Ads (v1) integration to add a request timeout option with a default value of 300 seconds.
Google Sheets (v1) bug fix: Return error descriptions
We’ve improved how our Google Sheets (v1) integration handles errors. The integration will now read status codes from API responses and return the error description when it is available.
Typeform (v1) update: Request timeout
We’ve improved our Typeform (v1) integration to add a request timeout option with a default value of 300 seconds.
Intercom (v1) bug fix: Reverted companies stream to incremental
We’ve fixed a bug in our Intercom (v1) integration, the companies stream was reverted to work as an incremental stream.
Intercom (v1) update: Improved logger messages
We’ve improved our Intercom (v1) integration by adding more descriptive logger messages.
Intercom (v1) bug fixes: Fixed breaking changes
We’ve fixed the following issues in our Intercom (v1) integration:
- The
epoch_milliseconds_to_dt_str()function was updated to convert epoch to UTC time. - The
time_extractedelement was added back to thewrite_recordfunction. - The bookmark for the
conversation_partsstream will be updated with the parentconversation’s replication key after the collection of child records.
Intercom (v1) bug fix: Added missing fields in the contact stream
We’ve fixed a bug in our Intercom (v1) integration causing missing fields in the contacts stream.
Zendesk (v1) update: Request timeout
We’ve improved our Zendesk Support (v1) integration to add a request timeout option with a default value of 300 seconds.
Mixpanel (v1) update: Request timeout
We’ve improved our Mixpanel (v1) integration to add a request timeout option with a default value of 300 seconds.
Yotpo (v1) update: Request timeout
We’ve improved our Yotpo (v1) integration to add a request timeout option with a default value of 300 seconds.
Zendesk (v1) update: Retry for 503 error
We’ve updated how our Zendesk Support (v1) integration handles 503 errors. Stitch will retry after a 503 error only if the Retry-After header is present in the response.
New feature: Multiple Destinations
Stitch Unlimited and Ulimited Plus accounts can now load data from their integrations into more that one destination! Learn more in the documentation.
Klaviyo (v1) update: Request timeout
We’ve improved our Klaviyo (v1) integration to add a request timeout option with a default value of 300 seconds.
GitHub (v1) update: Request timeout
We’ve improved our GitHub (v1) integration to add a request timeout option with a default value of 300 seconds.
Recharge (v1) update: Request timeout
We’ve improved our Recharge (v1) integration to add a request timeout option with a default value of 300 seconds.
Harvest (v2) update: Request timeout
We’ve improved our Harvest (v2) integration to add a request timeout option with a default value of 300 seconds.
Zendesk (v1) update: Retry for 5xx errors
We’ve improved how our Zendesk Support (v1) integration handles errors by adding a retry mechanism to all 5xx errors.
GitHub (v1) update: Support of objects in the parent field
We’ve updated our GitHub (v1) integration to add support of objects for the parent field in the teams stream.
Mambu (v2) update: New field in the loan_accounts stream
We’ve updated our Mambu (v2) integration to add an original_account_key field to the loan_accounts stream.
Mambu (v2) bug fix: Duplicated record in the audit_trails stream
We’ve updated our Mambu (v2) integration to add a number_last_occurrence value for bookmarks in the audit_trails stream. This solves the issue of duplicated records.
Shopify (v1) integration: New Events stream
A new events stream was added to our Shopify (v1) integration.
For more information, see the Shopify documentation.
Mambu (v2) update: Changes in the gl_journal_entries stream
We’ve updated our Mambu (v2) integration to change the replication_keys and bookmark_field for the gl_journal_entries stream from booking_date to creation_date.
This change solves the issue where journal entries were missing when transactions were reversed.
Facebook Ads (v1) update: Retry for job polling
We’ve improved our Facebook Ads (v1) integration to resolve race-condition errors. The integration will now retry when an error is encountered with AdsInsights job polling.
Amazon DynamoDB (v1) update: Increased precision for decimals
We’ve updated our Amazon DynamoDB (v1) integration to expand the decimal precision to match the max width of a singer.decimal.
Typeform (v1) update: Retry for ChunkedEncodingError
We’ve improved how our Typeform (v1) integration handles errors. The integration will now retry when a ChunkedEncodingError is encountered.
Typeform (v1) update: Pagination for landings
We’ve updated our Typeform (v1) integration to add pagination to the landings stream.
Typeform (v1) bug fix: IndexError issue in landings pagination
We’ve fixed an issue with our Typeform (v1) integration where an IndexError was returned when indexing the items list in landings pagination. Stitch will now check if items is empty.
Salesforce (v1) update: Increased request timeout
We’ve updated our Salesforce (v1) integration to increase the request timeout from 30 seconds to five minutes.
With this change, the integration can support objects that take longer than 30 seconds to return.
Mixpanel (v1) update: New error message for timezone issues
We’ve improved how our Mixpanel (v1) integration handles errors. An error message will now be returned when there is an issue related to timezones.
Mixpanel (v1) update: Switch from multipleOf to singer.decimal
We’ve updated our Mixpanel (v1) integration to use the type string and format singer.decimal in funnels and revenue streams, instead of the type number and 'multipleOf': 1e-20.
This change solves the issue where a schema mismatch error would be retuned when a value was out of range.
Mixpanel (v1) bug fix: timezone issue in date-time conversions
We’ve fixed an issue with our Mixpanel (v1) integration where timezones were ignored when writing UTC date-time values. The integration can now write the correct UTC date-time value based on the timezone in your Mixpanel project.
New integration: Crossbeam
A new Crossbeam integration is now available!
Get started by creating a new Crossbeam integration or learning more in our documentation.
Updated feature: Response for Import API access tokens
We’ve updated the response in the Stitch Connect API when retrieving access token IDs.
The Import API access token ID creation timestamp will now be included in the GET /v4/sources/{source_id}/tokens response. Check our docs to see an example.
LinkedIn Ads (v1) update: Improved handling of 4xx errors
We’ve improved how our LinkedIn Ads (v1) integration handles 4xx errors for the adCampaignGroup stream by returning custom messages and handling JSON decoding errors.
LinkedIn Ads (v1) update: Check account numbers
We’ve improved our LinkedIn Ads (v1) integration by adding a step that checks the account_number in discovery mode and returns an error if the account number is invalid.
LinkedIn Ads (v1) update: Automatically include replication keys
We’ve improved our LinkedIn Ads (v1) integration by including the replication keys as automatic fields.
Updated feature: Post-Load Webhooks API change
The Stitch Connect API and Application now require that you have a destination to create a post-load webhook.
In the Stitch Connect API, you now need to provide a Destination ID in the POST body. The destination_id parameter value should be the destination that will trigger the webhook. For more information, take a look at our docs on how to create a post-load webhook.
Use one of the following ways to find your Destination ID:
via the Connect API:
Call GET /v4/destinations
via the Web Application:
- Log into your Stitch account.
- Navigate to Destinations.
- Your ID is part of the web URL. Look for
/v2/destinations/<destination_id>/edit.
If you need additional help retrieving your Destination ID, please reach out to Stitch Support.
Stitch Connect JavaScript (Stitch.js) deprecation
As of today, the Stitch Connect JavaScript client, or Stitch.js, has been deprecated.
What does this mean?
Stitch.js will continue to function, but Stitch will no longer formally support its use.
Does this affect the Connect API?
The only endpoint affected by this change is the Create a Session endpoint. All other endpoints in the Connect API remain unchanged.
When will it stop functioning?
We don’t have a sunset, or end-of-life, date set just yet. If and when a sunset date is chosen, we’ll communicate it here and through other support channels.
What should you do instead?
If you’re using Stitch.js, transition to using parallel functionality in the Connect API.
The following table lists all Stitch.js functions, the Connect API endpoint that provides the same functionality, and links to resources that explain how to perform the functions in the API.
| Stitch.js function | Connect API endpoint | How-to guide |
| addSource | POST /v4/sources | |
| authorizeSource | PUT /v4/sources/{source_id} | |
| displayDiscovery | GET /v4/sources/{source_id}/streams | |
| selectStreamsForSource | PUT /v4/sources/{source_id}/streams/metadata | |
| editSource | PUT /v4/sources/{source_id} |
What about performing OAuth for sources?
The Connect API can still perform OAuth for sources that support it. Check out the Configure OAuth for a Data Source with the Connect API guide for step-by-step instructions.
PostgreSQL (v2) update: Google CloudSQL PostgreSQL now available!
A new version (v2) of our Google CloudSQL PostgreSQL integration is now available!
Along with all of the new features in v2 of the PostgreSQL integration (which this integration is based on), we’ve also added support for:
- SSL connections
- Log-based Incremental Replication
Learn more in our Google CloudSQL PostgreSQL integration documentation.
Databricks Delta (v1) update: Leaving beta!
Our Databricks Delta Lake (AWS) destination has left open beta and is now generally available! Check out the documentation for more info about this destination.
Amazon S3 CSV (v1) bug fix: Empty file error handling
Previously, the Amazon S3 CSV integration would not complete a replication job when multiple CSV files in an S3 bucket had empty records - even if there were some files that did have records.
This has been corrected. The integration will now complete replication jobs by ignoring the files without records.
Chargebee (v1) update: Restrictive properties removed
We’ve removed all minimum/maximum and minLength/maxLength restrictive properties from all Chargebee tables so that the integration can continue to sync with the evolving Chargebee API.
Chargebee (v1) update: New fields!
We’ve added new fields to the events and addons tables.
New to the events table:
show_descriptions_in_invoicesshow_description_in_quotesobjectsubattribute within thetiersattribute
New to the addons table:
show_descriptions_in_invoicesshow_description_in_quotesobjectsubattribute within theprice_in_decimalattribute
Chargebee (v1) improvement: New handling for JSONDecode errors
We’ve added new helpful error messages for the invoices and transactions streams when JSONDecode errors are encountered:
Sorry, authentication failed. Invalid api keyDid not get response from the server due to an unknown error
Google Search Console (v1) update: New empty response error exception
To improve the experience of our Google Search Console integration, we’ve changed how we handle empty response errors.
Instead of bypassing the error without an explanation, the integration will now raise an error and display it in the Extraction Logs:
HTTP-error-code: 400, Error: The request is missing or has a bad parameter.
Outreach (v1) update: New field!
A new field has been added to our Outreach (v1) integration!
The name field is now available for replication in the events table.
GitHub (v1) update: New empty response error exception
To improve the experience of our GitHub integration, we’ve changed how we handle empty response errors.
Instead of bypassing the error without an explanation, the integration will now raise an error and display it in the Extraction Logs:
HTTP-error-code: 400, Error: The request is missing or has a bad parameter.
Facebook Ads (v1) update: Fixed composite primary key for the `ads_insights_country` table
We’ve fixed the ads_insights_country composite primary key. The country field had previously been erroneously excluded.
The composite primary key is now: campaign_id : adset_id : ad_id : date_start : country
This is a breaking change and communiation from Stitch support has been emailed to affected users.
If you are not already including the country field in downstream processes that identify uniqueness of records in the files loaded for this table, this field will need to be added into those processes.
You may also wish to reset this table to have historical data re-replicated and more accurately portrayed, in which case you should:
- Contact our support team to implement a courtesy row-usage exemption for your Facebook Ads integration.
- Within Stitch, navigate to the
ads_insights_countrytable’s Table Settings page. - Use the Reset Table button to queue this table’s reset.
If you have any questions about the change or this process, please reach out to Stitch support via in-app chat.
Toggl (v1) update: Updated base API URLs
Toggl has updated their API information. We’ve updated the base of the API URLs we use to extract data from to ensure we are pulling information from the correct enpoints.
Shopify (v1) update: Updated setup requirements for Shopify Plus plans
We’ve updated our Shopify documentation to include info about the required permissions for users on Shopify Plus plans.
In general, view-level permissions should be sufficient to allow Stitch to replciate data. We recommend checking out Shopify’s Staff Permissions documentation for details on the permissions available inShopify.
Campaign Manager (v1) update: API version upgrade
We’ve upgraded the API version our Campaign Manager integration uses to extract data, from 3.2 to 3.5.
Yotpo (v1) improvement: Error handling and messaging
We’ve made some updates to our Yotpo integration that improves error handling and messaging during Extraction:
-
Fixed a transform error with the
unsubscriberstable. Previously, records without valid Primary Key values would result in a critical error that stopped extraction. Now, these records will be dropped and a message will display in the Extraction Logs. This allows Extraction to continue for records with valid Primary key values. -
Some errors now result in an automatic retry. Previously, if the integration received certain response codes from Yotpo’s API, Stitch would stop Extraction. The following response codes now trigger an exponential backoff and then automatic retry:
Response code Message 401 Invalid authorization credentials. 429 The API rate limit for your organisation/application pairing has been exceeded. 502 Server received an invalid response. 503 API service is currently unavailable. 504 API service time out, please check Yotpo server.
Yotpo (v1) bug fix: Corrected Replication Method for tables
We’ve corrected the Replication Method for a few Yotpo tables in the docs. These tables were listed as using Key-based Incremental Replication, but in fact are Full Table:
productsunsubscribers
Pipedrive (v1) update: Removed delete_log table
Due to Pipedrive removing support for delete_logs from their API, we’ve removed this table from our Pipedrive integration. We’ve also updated the docs to reflect this.
Pipedrive (v1) bug fix: Corrected Replication Method for tables
We’ve corrected the Replication Method for a few Pipedrive tables in the docs. These tables were listed as using Key-based Incremental Replication, but in fact are Full Table:
activity_typesfilterspipelinesstagesusers
New documentation: Understanding integration versioning and statuses
After the v2 release of our PostgreSQL integration, we received some questions about how integrations are versioned. Today, we’re adding a new resource to the docs to help answer these questions: Understanding Integration Versioning and Upgrades in Stitch
This new guide contains info about the process each version of our integrations goes through, what each version status (ex: Beta, Released (Testing) means, and how to identify which version of an integration you’re using.
Amazon S3 CSV (v1) bug fix: Corrected type checking for integers and numbers
Previously, data type checking for integer and number data types wasn’t explicitly enforced, which resulted in some integer data being incorrectly typed. This has been corrected.
New feature: Connection Cloning
We’ve expanded our Stitch features!
In the web app or with Connect, you can now clone your Stitch connections. Check out the new step-by-step guide for help setting that up.
Chargebee (v1) update: New item tables for Chargebee Product Catalog v2!
We’ve made some big changes to how our Chargebee integration works, along with adding some new tables.
(v1) integrations now use the Product Catalog version for the site to determine which tables to display in Stitch. Some tables and fields are only available if your site is using v1.0 of the Product Catalog, some only on v2.0. We’ve added a new section to the documentation that goes into more detail.
In addition to this change, we’ve added a few new tables which are available if using Product Catalog v2.0:
Note: Stitch’s (v1) integration supports both Product Catalog v1.0 and v2.0. The version of the integration doesn’t refer to support for a specific Product Catalog version.
Square (v1) update: item_data object removed from orders table
The item_data object has been removed from Square’s orders table. We removed this object due to it being undocumented by Square and not being returned by Square’s API.
Outreach (v1) update: New tables and foreign key documentation
We’ve added some new tables to our Outreach (v1) integration:
sequence_statessequence_stepssequence_templatessequences
We’ve also updated the Outreach table documentation to include info about foreign keys and how tables related to each other. Check it out here.
Chargebee (v1) bug fix: Correct issue with cf_company_id data type
Previously, Chargebee integrations could encounter issues related to data typing when replicating the cf_company_id field in the customers and events table. We’ve addressed this by allowing this field to be either an integer or a string.
Harvest Forecast (v1) bug fix: Correct sync_endpoints method
This update fixes an issue in Harvest Forecast integrations where data replication would fail due to incorrectly ordered objects in the integration’s code. Additionally, this change also removes duplicate items from the integration’s output.
Amazon S3 CSV (v1) improvement: Duplicate column headers and extra value support
Our Amazon S3 CSV integration now supports duplicate column headers and extra values in rows. We’ve added an additional system column (_sdc_extra) to support these scenarios.
Check out the Amazon S3 CSV docs for more info and examples.
Harvest (v2) update: Updated API request headers
We’ve updated the headers our Harvest (v2) integration uses to make API calls to align with the recent changes made by Harvest.
API documentation update: New guide for creating destinations
We’ve added a new guide to the Connect API resources!
Use the Create a Destination with the Connect API guide to learn how to connect a destination to your Stitch account using the API. You can also use this guide to learn about the process for switching to a different destination.
API documentation update: Improved connection property docs
We’ve moved the documentation for connection property objects out of the Connect API reference and into their own reference: Destination and Source Connection Property API Reference
This new resource includes:
- An explanation of what connection properties are and how to use them
- Info about what connections are available in the API
- Details about the properties required to create and configure each available connection using the API
ReCharge (v1) update: New rate limit handling
We’ve updated how our Recharge (v1) integration makes requests to the Recharge API to ensure Stitch doesn’t exceed Recharge’s rate limit.
Mambu (v2) bug fix: Corrected handling for lists of custom fields
We’ve updated the Mambu integration to correctly handle lists of custom fields. Previously, the integration would drop lists (arrays) of custom fields. Lists of custom fields will now be correctly saved and replicated.
PostgreSQL (v2) update: Leaving beta!
A new version (v2) of our PostgreSQL integration has left beta and is now generally available!
This version (v2) of Stitch’s PostgreSQL integration optimizes replication by utilizing Avro schemas to write and validate data, thereby reducing the amount of time spent on data extraction and preparation. Compared to previous versions of the PostgreSQL integration, this version boasts increased performance and overall reduced replication time.
Notable improvements and changes in this version also include:
- Expanded data type support. This version supports additional PostgreSQL data types. Refer to the PostgreSQL data types documentation for more info.
- Improved handling of
JSON,JSONB, andHSTOREdata types. In previous versions, these data types were treated as strings. This version will send them to your destination as JSON objects, which may result in de-nesting. - Improved handling of schema changes in tables using Log-based Incremental Replication. Adding and removing columns in these tables will no longer cause extraction errors. Note: This limitation still applies to version 1.
Note: The following features aren’t fully supported, but are being worked on:
- Arrays of
DECIMAL,NUMERIC, andTIMESTAMP(TZ)data types - Support for other flavors of PostgreSQL. We’re in the process of testing this version of our integration with other flavors of PostgreSQL, including Heroku, Google CloudSQL, Amazon Aurora, and Amazon RDS.
To get a look at how this version compares to the previous version of PostgreSQL, refer to the PostgreSQL version comparison documentation.
Chargify (v1) update: New transaction data!
New fields have been added to the transactions table of our Chargify (v1) integration:
period_range_startperiod_range_endprice_point_idprice_point_handlecomponent_handlecomponent_price_point_idcomponent_price_point_handle
Learn more in our documentation.
Chargify (v1) update: New component data!
New fields have been added to the components table of our Chargify (v1) integration:
default_price_point_nameproduct_family_nameprices.idprices.component_idprices.starting_quantityprices.ending_quantityprices.unit_priceprices.price_point_idprices.formatted_unit_price
Learn more in our documentation.
Shopify (v1) update: Product status now available!
A new status field has been added to the products table of our Shopify (v1) integration.
This field indicates the current status of a given product, including as active, archived, and draft.
Klaviyo (v1) update: New campaigns table and field selection support!
We’ve made some updates to our Klaviyo integration:
- Field selection is now supported! Select only the fields you want to replicate in the Tables to Replicate tab.
- New
campaignstable. This table contains info about the campaigns in your Klaviyo account.
Learn more in our documentation.
Freshdesk (v1) improvement: Correct data type for groups table field
We’ve added integer as a valid data type for the groups.auto_ticket_assign field. Previously, the integration would only accept boolean values for this field.
As the Freshdesk API can return boolean or integer values, the integration’s data typing could cause errors or discrepancies. This improvement ensures data is replicated correctly and without issue.
GitHub (v1) update: New table documentation now available
We’ve updated the GitHub (v1) docs with info about the following tables:
commit_commentscommitseventsissue_labelsissue_milestonesproject_cardsproject_columnsprojectspull_request_reviewsteam_membersteam_membershipsteams
Check out the updated docs for more info.
Documentation update: Parent and child table info now available
We’ve updated the integration schema documentation to include info about parent and child tables. Now you can tell, at a glance, if a table is dependent upon another table for replication:
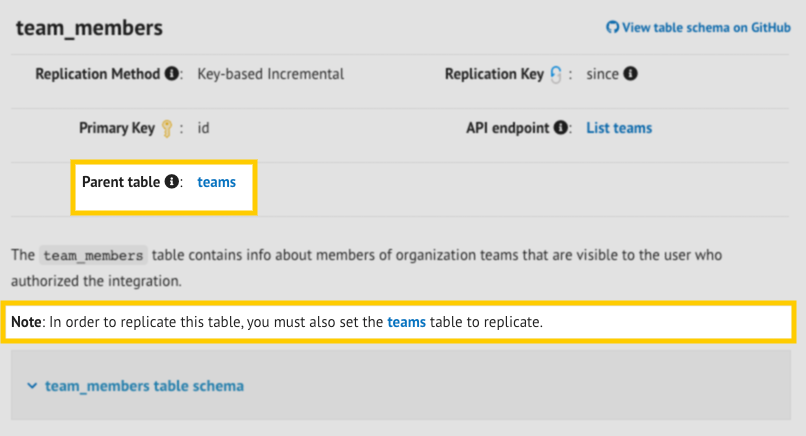
The Parent table field contains the name of the table that must also be selected for the child table to replicate successfully. This info will also be included in the child table’s description. In this example, the teams table must be selected for the team_members table to replicate.
For parent tables, their descriptions will contain info about the child tables that depend on them:
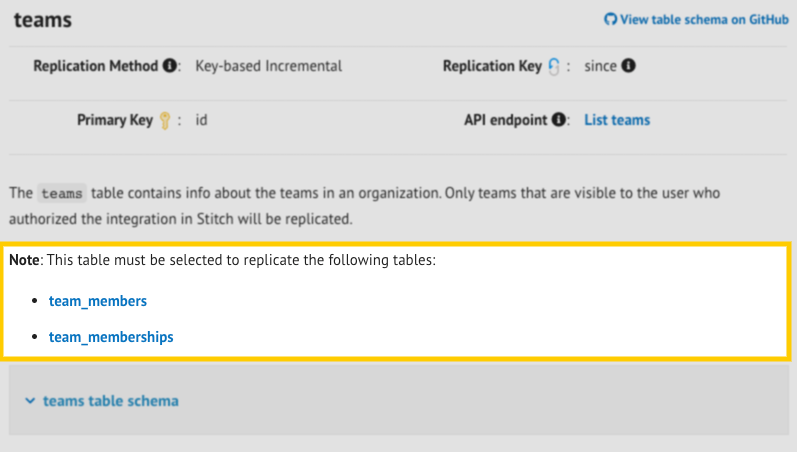
In this example, the team_memberships and team_members tables will only replicate successfully if the teams table is also selected.
We hope this additional info about integration tables provides additional insight into how Stitch replicates data and will help you avoid Extraction errors.
Currently this data is only available in the GitHub (v1) docs, but we’ll roll it out to other integrations as we make updates.
Pipedrive (v1) removal: Removed delete_logs table
We’ve removed the delete_logs table from our Pipedrive integration, as Pipedrive has removed support for it.
Pipedrive (v1) improvement: Retrieve all organization fields
Previously, fields would be missing from the organizations table if there were more than 100 fields available. We’ve added pagination to the requests the integration makes for organizations data, ensuring all fields will be discovered and replicated correctly.
Pipedrive (v1) improvement: Error handling and retries
We’ve improved how our Pipedrive integration handles errors. Previously, the integration wouldn’t retry errors when they were received from the Pipedrive API. The integration will now retry when errors are encountered for any table.
Slack (v1) update: User email now available in users table
We’ve added a new column to the Slack users table: profile.email. This column contains the email address for the associated user.
Note: To replicate this data, you’ll also need to grant the users:read.email scope to the Stitch app created for the integration.
Typeform (v1) update: New forms table!
We’ve added a new table to our Typeform (v1) integration!
The new forms table contains info about the forms accesible to the user who authorized the Typeform integration in Stitch.
Learn more in our documentation.
Facebook Ads (v1) API upgrade to v10.0
The Facebook Ads integration now replicates data using version 10.0 of the Facebook Marketing API. For more details, view the Facebook API changelog.
Shopify (v1) improvement: Improved data typing for abandoned checkouts
Previously, some users were encountering JSON schema validation errors for the abandoned_checkouts table due to how some columns were being typed. This change types the following columns correctly, eliminating the validation errors:
note_attributesline_items.applied_discountsshipping_lines.applied_discountsshipping_lines.custom_tax_lines
Check out the pull request for more info.
Pendo (v1) update: New setting for including anonymous visitor data
We’ve added a new setting to our Pendo integration: Include Anonymous Visitors
When checked, Stitch will replicate data attributed to anonymous visitors.
Learn more in our Pendo integration documentation.
Microsoft SQL Server (v1) bug fix: Quoting Replication Key columns in incremental queries
Previously, the names of Replication Key columns weren’t being quoted when used in incremental queries. If a column name contained spaces, this would cause an error in the query and extraction to fail. This fix ensures Replication Key columns are properly quoted.
New extraction error reference for Salesforce
We’ve added a new resource for troubleshooting Extraction errors in Salesforce integrations. If Stitch receives an error during Extraction, you can use this reference to locate the error, pinpoint the cause, and identify next steps for resolution.
Intercom (v1): Identified issue with companies endpoint
We’ve identified an issue replicating data for the companies table in Intercom (v1) integrations due to a limit in Intercom’s API.
Currently, Intercom’s API allows an Intercom app to make one request to the Scroll over all companies endpoint at a time. Stitch uses this endpoint to replicate the companies table.
If multiple connections exist and they attempt to use this endpoint at the same time, only the connection who made the request first will succeed.
This means that if Stitch attempts to extract data when another connection is using the endpoint, Extraction will fail and an error will surface in the Extraction Logs.
We’ve updated the Intercom documentation to include this info and how to mitigate it. Additionally, we’ve created a new resource for troubleshooting Intercom Extraction errors.
Shopify (v1) bug fix: Remove duplicates of `build` fields
Due to the case sensitivy of fields during the Shopify replication job, Stitch failed to recognize that build and Build were the same field.
This fix canonicalizes these fields. Whenever Stitch sees Build, it will transform it to build to ensure all build data goes into the same field.
Facebook Ads (v1) update: Increased replication job timeout
We’ve increased the timeout from 120 seconds to 300 seconds for Facebook Ads Ads Insights replication jobs.
Zuora (v1) update: Enforce use of UTC
Our code is now explicitly forcing the use of UTC for timestamps for our Zuora integration.
Our requests to the Zuora REST API weren’t specifying a timezone while querying, and the integration assumed that no timezone retrieved meant UTC. This update ensures times are consistently recorded in a UTC format.
Shopify (v1) improvement: Improvements to order_refunds and transactions tables
We’ve made some improvements to how the transactions and order_refunds tables replicate in Shopify (v1) integrations:
- Bookmarking has been added to the
order_refundsandtransactionstables - Error handling added to the
transactionstable to avoid 429 errors
Shopify (v1) update: API upgraded to Shopify v2021-04
We’ve updated the Shopify integration’s API version fom 2020-10 to 2021-04.
Xero (v1) improvement: New wait time for rate limiting
We’ve added a minute-long wait time to the retry logic for the Xero integration. This ensures that Stitch doesn’t make too many requests to Xero’s API when retrying on a 429 error.
Marketo (v1) improvement: Improved Stitch compatibility
We’ve improved Marketo’s compatibility with Stitch by removing CR and CRLF characters from CSV files. Previously, Extraction would fail due to CR and CRLF characters appearing in unquoted fields.
Mambu integration: New version (v2) now available!
A new version (v2) of our Mambu integration is now available!
We’ve improved the naming of custom fields by reducing their size. Removing unnecessary characters in these fields improves the Mambu integration’s compatibility with PostgreSQL destinations by reducing the likelihood of field names exceeding the character limit for column names.
Here’s a look at how the schema for custom fields has changed:
| v2 attribute name | v1 attribute name |
|
custom_fields |
custom_field_sets |
|
custom_fields.field_set_id |
custom_field_sets.custom_field_set_id |
|
custom_fields.id |
custom_field_sets.custom_field_values.custom_field_id |
|
custom_fields.value |
custom_field_sets.custom_field_values.custom_field_value |
Learn more in our Mambu integration documentation.
PostgreSQL (HP) (v2) integration: Removed support for Composite, Range and OID types
We’ve removed support for Composite Types, Range Types and Object Identifier Types from our PostgreSQL integration.
Harvest Forecast (v1) improvement: Corrected replication for Full Table and assignments
This fix addresses a few issues:
-
Replication for
assignments: This table now replicates using Full Table Replication. Previously, Stitch would encounter errors from Harvest’s API when attempting to replicate data incrementally. We’ve determined this was caused by a change in Harvest’s API, so we changed this table’s Replication Method to accommodate that change. -
Full Table Replication: Stitch will now correctly refresh tables using Full Table Replication.
MySQL integration: New version (v2) now in beta
A new version (v2) of our MySQL integration is now in beta!
This version (v2) of Stitch’s MySQL integration optimizes replication by utilizing Avro schemas to write and validate data, thereby reducing the amount of time spent on data extraction and preparation. Compared to previous versions of the MySQL integration, this version boasts increased performance and overall reduced replication time.
Notable improvements and changes in this version also include:
- New column (field) naming rules. Avro has specific rules that dictate how columns can be named. As a result, column names will be canonicalized to adhere to Avro rules and persisted to your destination using the Avro-friendly name. Refer to the Column name transformations section in the MySQL docs for more info.
- Expanded data type support. This version supports additional MySQL data types. Refer to the MySQL data types documentation for more info.
Note: The following features aren’t currently supported, but will be before the integration leaves beta:
- Custom SSL certificates and certificate authorities
To get a look at how this version compares to the previous version of MySQL, refer to the MySQL version comparison documentation.
Xero (v1) update: Replicating archived contacts
Archived contacts can now be included in replication for Xero integrations.
To replicate records for both archived and active contacts:
- In the Stitch app: Check the Include archived contacts setting in the Integration Settings page
- In the Connect API: Set the
include_archived_contactsproperty forplatform.xerototrue
If this setting isn’t enabled, Stitch will replicate data only for active contacts.
Shopify (v1) bug fix: Allow null values for `definitions.customer` field
Previously, the customer object in the definitions table would only accept populated values. If the integration encountered a null value, Extraction would fail. This has been fixed.
Pendo (v1) bug fix: Fixed replication issue for track_events table
This bug fix resolves the following 400 error for Pendo integrations where the track_events table is selected:
bad pipeline: bad source: bad parameters for source type trackEvents: unexpected parameters`.
We corrected the source parameter for the trackEvents source from trackId to trackTypeId, allowing this table to now replicate successfully.
Improved security documentation
We’ve been working hard to improve our security documentation - here’s a high-level look at the changes:
-
Added a dedicated category page, ensuring you can easily view and navigate all things Stitch security
-
Reformatted the Security FAQ (now the Security Overview), allowing you to view all content at once. You can also now use
Ctrl+Fto perform an on-page search. -
Expanded the Security Overview to include detailed info about:
GitHub (v1) update: New base branch data available for pull_requests
Several fields have been added to the pull_requests table in our GitHub (v1) integration!
The base object contains details about the base branch used in a given pull request, including the repository it originated from.
Learn more in our documentation.
Xero (v1) update: New quotes table
A new table (quotes) has been added to our Xero (v1) integration!
Learn more in our documentation.
Xero (v1) update: Increased precision for CurrencyRate values
We’ve increased the CurrencyRate field’s precision from six decimals to 10. This affects all tables that contain this field.
New feature: Support for SSO with PingFederate
We’ve expanded our list of supported Identity Providers to include PingFederate!
Using a SAML SP connection, you can now configure Stitch to use SSO with your PingFederate instance. Check out the new step-by-step guide for help getting set up.
MailChimp (v1) improvement: Improved timeout message for campaigns
We’ve updated the export timeout error message for the campaigns table to indicate that the export will continue to be extracted in the next replication:
Mailchimp campaigns export is still in progress after [number] seconds. Will continue with this export on the next sync.
Previously, this message (campaigns - export deadline exceeded ([number] secs)) didn’t clearly set expectations for the table during the next replication job.
Xero (v1) improvement: Improved handling of Xero API errors
We’ve added features to more gracefully handle error responses from the Xero (v1) API, including exponential backoffs on 429 errors, credential checking support, and more detailed error messages.
Klaviyo (v1) improvement: Error logging improvements
Errors that stop Extraction will now display in the Extraction Logs. Previously, these errors wouldn’t be included, resulting in confusion about the cause of the error.
JIRA (v2) update: New components table
A new table (components) has been added to our JIRA (v2) integration!
Learn more in our documentation.
Xero (v1) improvement: Improved error handling with retry logic
We’ve added retry logic to Xero (v1) integrations. This allows the integration to automatically retry API requests when it receives certain errors from the Xero API.
Zuora (v1) improvement: AQuA API CSV handling improvement
We’ve improved how Zuora (v1)integrations handle truncated CSVs received from the Zuora API.
For more info about this new feature, check out the pull request in the tap-zuora repository.
New feature: Support for SSO with Azure Active Directory (Azure AD)
We’ve expanded our list of supported Identity Providers to include Microsoft Azure Active Directory (Azure AD)!
Using a generic SAML 2.0 app, you can now configure Stitch to use SSO with your Azure AD instance. Check out the new step-by-step guide for help getting set up.
PostgreSQL (v2) update: Key-based Incremental Replication now available!
The v2 version of our PostgreSQL integration, which is currently in open beta, now supports Key-based Incremental Replication. All of Stitch’s supported Replication Methods are now available for this version - go try it out!
New feature: Integration changelogs
Introducing: Integration changelogs!
Check out the history of our integrations and stay in the loop on updates with dedicated changelogs for these integrations:
We’ll add changelogs for other popular integrations and destinations in the weeks to come. If there’s a specific integration you’d like to see us work on, let us know by creating an issue in the Stitch Docs GitHub repo.
Salesforce (v1) update: Removed FieldHistoryArchive object
We’ve determined that the FieldHistoryArchive object is incompatible with the Salesforce integration’s current method of querying, and as a result have removed it from the integration.
Refer to the tap repository for more info.
Google Analytics (v1) update: Lifetime Value and Cohorts documentation
Stitch Support has determined that Lifetime Value and Cohorts aren’t currently supported for Google Analytics integrations, despite being available fields in Stitch. We’ve updated our documentation to reflect this and will address this issue in the app shortly.
Eloqua (v1) update: Email groups and additional contact data
We’ve added some additional data to our Eloqua (v1) integration!
- New table:
email_groups - New
contactfields:IsBounceBackIsSubscribedEmailFormatAccountName
Learn more in our documentation.
Mambu (v1) bug fix: Resolved decimal precision failures
Previously, if Stitch extracted decimal data larger than the constraint defined in the Mambu integration (1e-10), data validation would fail and result in Extraction errors.
The integration has been updated to expand the constraint, ensuring that big decimal values will no longer result in validation failures.
Salesforce (v1) improvement: Improved OPERATION_TOO_LARGE error messaging
We’ve updated the Salesforce integration to log OPERATION_TOO_LARGE errors more clearly. The following error will now display in the Extraction Logs when this issue is encountered:
OPERATION_TOO_LARGE: exceeded 100000 distinct who/what's. Consider asking your Salesforce System Administrator to provide you with the `View All Data` profile permission. (Stream: [STREAM_NAME])
Zoom (v1) update: Updated data for report_meetings and report_webinars tables
We’ve made a few updates to the Zoom report_meetings and report_webinars tables
- The
deptattribute in both tables now correctly returns anintegerinstead of astring - We’ve added the
host_idanduser_idfields to thereport_webinarstable
Pendo (v1) improvement: Improve performance for visitors and events tables
We’ve implemented ijson, which is used in other Singer taps, to streamline replication for Pendo’s visitors and events tables. This improvement reduces the amount of memory needed to replicate large amounts of data, potentially leading to improved Extraction times.
MongoDB (v2) bug fix: Duplicate database instances removed
This improvement removes duplicate instances of databases from the list of discovered databases in the Stitch MongoDB inegration.
Zuora (v1) improvement: Updated discovery process for new enforced limit on AQuA jobs
The new discovery process helps avoid Zuora integration failures due to the new enforcement of limits on AQuA jobs. For more information on Zuora’s AQuA API, click here.
New feature: Single Sign-on (SSO) with Okta and OneLogin
Stitch accounts can now be configured to use Single Sign-on (SSO) with Okta or OneLogin. Once enabled, team members would be required to authenticate with your Identity Provider (IdP) to access Stitch.
SSO is available for all Stitch plans.
Learn more in the documentation.
Salesforce (v1) improvement: Error message formatting
There are now actionable error messages when QUERY_TOO_COMPLICATED errors are encountered for the Salesforce integration.
Pendo (v1) bug fix: Custom field issues for visitors and accounts tables
We’ve fixed a few issues with the Pendo visitors and accounts tables:
- Custom fields without a defined data type will no longer return a
nullvalue. - If a table had multiple custom fields, the last field on the table was being overwritten. We’ve updated the integration to address this.
Google Ads (v1) improvement: New custom messages for common errors
We’ve updated the Google Ads integration to return actionable messages when Stitch encounters errors during Extraction. These messages now include the cause of the error, ensuring you can take action to resolve it.
Facebook Ads (v1) update: New ads_insights.unique_outbound_clicks data
We’ve added the unique_outbound_clicks field to each of the ads_insights_* tables in the Facebook Ads (v1) integration.
Xero (v1) bug fix: Date-time correction
Previously, the integration would truncate date-time data with a format of "\/Date(1419937200000+0000)\/" to date only.
This fix ensures that the time component of date-time values are correctly preserved.
PostgreSQL integration: New version (v2) now in beta
A new version (v2) of our PostgreSQL integration is now in beta!
This version (v2) of Stitch’s PostgreSQL integration optimizes replication by utilizing Avro schemas to write and validate data, thereby reducing the amount of time spent on data extraction and preparation. Compared to previous versions of the PostgreSQL integration, this version boasts increased performance and overall reduced replication time.
Notable improvements and changes in this version also include:
- New column (field) naming rules. Avro has specific rules that dictate how columns can be named. As a result, column names will be canonicalized to adhere to Avro rules and persisted to your destination using the Avro-friendly name. Refer to the Column name transformations section in the PostgreSQL docs for more info.
- Expanded data type support. This version supports additional PostgreSQL data types. Refer to the PostgreSQL data types documentation for more info.
- Improved handling of
JSON,JSONB, andHSTOREdata types. In previous versions, these data types were treated as strings. This version will send them to your destination as JSON objects, which may result in de-nesting.
Note: The following features aren’t currently supported, but will be before the integration leaves beta:
- Key-based Incremental Replication
ARRAYdata type
To get a look at how this version compares to the previous version of PostgreSQL, refer to the PostgreSQL version comparison documentation.
Shopify (v1) improvement: Standardized error messages
Previously, error messages related to misconfigured Shopify shops were unclear and non-standard in format. These errors have been standardized to provide a more consistent experience and message.
Stripe (v1) bug fix: Removed fields causing issues
The custom_fields object in the Stripe (v1) integration invoices table have been removed, as they were causing issues.
Stripe (v1) update: New fields!
New fields have been added to our Stripe (v1) integration!
The following tables now have additional fields available for replication:
chargescustomersinvoice_itemsinvoice_line_itemsinvoicespayoutssubscription_itemssubscriptions
Learn more in our documentation.
Mambu (v1) update: New tables and updated API endpoints
We’ve added some new tables to the Mambu integration:
We’ve also updated the endpoints the integration uses to extract data for the following tables:
clients- Previously usedGet all clients, now usesSearch clientsgroups- Previously usedGet all groups, now usesSearch groupsgl_journal_entries- Previously usedGet all GL journal entries, now usesSearch for GL journal entries
Learn more in our Mambu integration documentation.
QuickBooks integration: New version (v1)
A new version (v1) of our QuickBooks integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from QuickBooks to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
quickbooks_prefixes on table names - User-facing Extraction Logs
- Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new QuickBooks integration or learn more in the updated documentation.
Availability of European Data Center
We’re proud to announce the availability of an AWS European Data Center for Stitch. Enjoy the benefits of Stitch while ensuring your extracted data never leaves the European Union. Signup to get started or see our documentation for more details.
Google Analytics (v1) integration leaving open beta
Our Google Analytics integration has left open beta and is now generally available! Check out the docs for more info.
Trello integration: New version (v1)
A new version (v1) of our Trello integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Trello to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
trello_prefixes on table names - Native OAuth support
- Support for custom fields for the
boardsandcardstables - User-facing Extraction Logs
- Updated API secret authentication
- The
exporttable now uses Append-only loading behavior - Configurable attribution windows for the
export,funnels, andrevenuetables - Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new Trello integration or learn more in the updated documentation.
Square integration: New version (v1)
A new version (v1) of our Square integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Square to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
square_prefixes on table names - Addition of the customers table
- Several renamed tables:
square_inventoryis nowinventoriessquare_locationis nowlocations
- Several record types are now replicated through top-level tables:
feedata is now replicated through thetaxestabletimecarddata is now replicated through theshiftstable
- Removal of the
square_pagestable due to its deprecation in the Square API - User-facing Extraction Logs
- Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new Square integration or learn more in the updated documentation.
Mixpanel integration: New version (v1)
A new version (v1) of our Mixpanel integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Mixpanel to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
mixpanel_prefixes on table names - New tables, including:
- User-facing Extraction Logs
- Updated API secret authentication
- The
exporttable now uses Append-only loading behavior - Configurable attribution windows for the
export,funnels, andrevenuetables - Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new Mixpanel integration or learn more in the updated documentation.
AdRoll integration: New version (v1)
A new version (v1) of our AdRoll integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from AdRoll to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
adroll_prefixes on table names - User-facing Extraction Logs
- Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new AdRoll integration or learn more in the updated documentation.
Intercom integration: New version (v1)
A new version (v1) of our Intercom integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Intercom to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Use of Intercom API version 2.0
- Updated OAuth flow for easier authentication
- New tables, including:
- contacts (formerly (
users) - contact_attributes
- company_attributes
- teams
- contacts (formerly (
- Additional field support for the conversations table, including:
conversation_ratingssla_appliedstatistics
- Enhanced extraction approaches for the
contactsandcompaniestables - User-facing Extraction Logs
- Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new Intercom integration or learn more in the updated documentation.
Increased timeouts on integration extractions
We’ve increased timeouts for extractions for source integrations from 6 hours to 23.5 hours. This change will enable customers with large data sets to continue replicating data without the need to restart replication.
Google Analytics (v1) integrations: Use accountSummaries: list to fetch profiles
Google Analytics integrations will now use accountSummaries to fetch Google Analytics profiles available for the user authorizing the integration. We’ve made this change to reduce the number of queries Stitch makes to Google Analytics and overall API quota usage.
Integrations leaving beta
The following integrations have left beta and are now generally available. Get started with these integrations today!
Salesforce (v1) integrations: Remove NetworkUserHistoryRecent object
We’ve determined that the NetworkUserHistoryRecent object is incompatible with the Salesforce integration’s current method of querying, and as a result have removed it from the integration.
Refer to the tap repository for more info.
PostgreSQL (v1) integrations: Include partitioned tables in discovery
Previously, partitioned tables weren’t being detected during Discovery for PostgreSQL (v1) integrations. This has been corrected.
Facebook Ads (v1) API upgrade to v8.0
The Facebook Ads integration now replicates data using version 8.0 of the Facebook Marketing API. For more details, view the Facebook API changelog.
Google Analytics (v1) integrations: Reduced retry aggressiveness
We’ve improved the retry logic for Google Analytics to make retries less aggressive, ideally reduceing the consumption of daily API quotas.
New integrations in open beta
Stitch is pleased to announce the release of three new integrations into open beta and available to all customers:
All three of these integrations are available to all customers in open beta and can be added to your account through the integrations page.
Select All tables and columns functionality now available for Facebook Ads and Salesforce
You can now quickly and easily select and de-select all tables and columns within Facebook Ads and Salesforce integrations!
New integrations in open beta
Stitch is pleased to announce the release of several new integrations into open beta:
In addition to providing more tables, these integrations now include table and column selection, Extraction Logs, Loading Reports and full Connect API compatibility!
Salesforce (v1) integrations: Remove DataType object
We’ve determined that the DataType object is incompatible with the Salesforce integration’s current method of querying, and as a result have removed it from the integration.
Refer to the tap repository for more info.
Google Analytics (v1) integrations: Non-retryable error messages now in Extraction Logs
Error messages from HTTP 4xx codes that aren’t retryable will now include details from Google Analytics detailing what the issue is. Previously, these messages weren’t included in Extraction Logs, leading to confusion about the issue causing the error.
Google Analytics (v1) update: Improved handling of retryable errors
We’ve updated the retry logic for our Google Analytics integration to include HTTP codes 403 and 429. In the event that Stitch receives these responses from Google Analytics, the integration will exponentially back off and retry.
Google Analytics (v1) update: Improved parsing of datetimes
Previously, fields in the Time group could cause errors during Extraction, as they were returned from Google’s API using a non-ISO format.
These fields are now parsed as datetime and converted to ISO-8601 (UTC) during Extraction.
Salesforce (v1) integrations: LoginEvent is now Full Table
We’ve determined that the LoginEvent object doesn’t support ordering by CreatedDate, meaning that Stitch can’t reliably replicate this data incrementally. This table now has a forced Replication Method of Full Table.
Google Analytics (v1) update: Remove searchKeyword as default Behavior Overview field
As searchKeyword isn’t data that Google Analytics collects by default, we’ve removed it from the default fields selected for replication for the Behavior Overview report. This field will still be available in Stitch, just not selected by default.
Pardot integration: New version (v1)
A new version (v1) of our Pardot integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Pardot to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of `` prefixes from table names
- New tables, including:
- User-facing Extraction Logs
- Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new Pardot integration or learn more in the updated documentation.
Google Analytics (v1) update: Pre-made reports now available
We’ve added a handful of pre-made reports to our our Google Analytics (v1) integration:
- Audience Overview: Audience metrics including page views, users, bounce rate and more
- Audience Geo Location: A breakdown of your audience by geographical location
- Audience Technology: The browsers, operating systems, and devices your users employ
- Acquisitions Overview: The performance of your users across traffic sources and mediums
- Behavior Overview: Pages visited and actions performed on your website
- Ecommerce Overview: A breakdown of your transactions by traffic source
These reports will display as tables available for selection in the Tables to Replicate tab of all Google Analytics (v1) integrations. Check out this easy way to get started with Google Analytics data!
GitHub (v1) update: Team memberships and new fields now available!
We’ve made some updates to our GitHub (v1) integration, including some a new table and additional fields!
Here’s a look at the changes:
team_memberships: New table! Includes membership data for team members in repositories specified for the integration.project_cards: New fields:_sdc_repository,cards_url,nameissue_milestones,project_columns,team_members: Added the_sdc_repositoryfieldprojects,pull_request_reviews,teams: Minor data formatting changes
Salesforce (v1) integrations: Improved PK chunking error messages
Error messages resulting from PK (Primary Key) chunking in Salesforce integrations have been extended. Previously, only timeout issues were covered by the integration. This improvement adds logic that covers additional situations, such as failure to write query results.
Salesforce (v1) integrations: Location data types unsupported for Bulk API
We’ve determined that the locations fields aren’t supported by the Salesforce Bulk API. If selected, the following erorr will surface during Extraction:
[FIELD_NAME] cannot query compound address fields or geolocations with bulk API
Refer to the tap repository for more info.
New version (v1) of Google Analytics integration in open beta!
A new version (v1) of our Google Analytics integration is now in open beta!
We’ve worked hard to ensure this new integration is the best way to extract data from Google Analytics to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Support for creating multiple custom reports
- Custom metric and dimension support
- User-facing Extraction Logs
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
Get started today by creating a new Google Analytics integration or learn more in the updated documentation.
Databricks Delta Lake destination in open beta
A new destination is now in open beta, available to all customers: Databricks Delta Lake (AWS).
Developed by Databricks, Delta Lake is an open-source storage layer that leverages the “lakehouse” paradigm. This allows you to implement similar data structures and data management features to those of a data warehouse, directly on the kind of low cost storage used for data lakes.
Check out the docs for more information.
GitHub (v1) update: New tables!
New tables have been added to our GitHub (v1) integration!
The following tables are now available for replication:
commit_commentscommitseventsissue_labelsissue_milestonesproject_cardsproject_columnsprojectspull_request_reviewsteam_membersteams
GitHub (v1) update: Squashed pull request commit data now available!
We’ve added a new table to our GitHub (v1) integration: pr_commits.
This table is a slight modification of the existing commits table, but allows you to associate commits to pull requests that have been squash merged.
PostgreSQL (v1) integrations: Correctly use SSL connections
We’ve fixed an issue with PostgreSQL (v1) integrations where SSL connections weren’t being used, even if the SSL option was checked in Stitch. If checked, Stitch will now correctly use and enforce SSL when connecting to the database.
Facebook Ads (v1) API upgrade to v6.0
The Facebook Ads integration now replicates data using version 6.0 of the Facebook Marketing API. For more details, view the Facebook API changelog.
PostgreSQL (v1) integrations: Correctly display BYTEA data as unsupported
Previously, Stitch would display columns typed as BYTEA as available for selection, despite this data type currently being unsupported for PostgreSQL (v1) integrations. With this fix, these columns will now correctly display as UNSUPPORTED in Stitch.
In-app notification dismissal
Error notifications can now be dismissed in the Stitch app! To do so, navigate to the Notifications tab and click Dismiss next to the notification you want to remove.
Facebook Ads (v1) integrations: New ads_insights.video_play_curve_actions data
We’ve added the video_play_curve_actions field to each of the ads_insights_* tables in the Facebook Ads (v1) integration.
PostgreSQL (v15-10-2015) sunset
The v15-10-2015 version of our PostgreSQL integration has been sunset. As of today, this version of the PostgreSQL integration has been removed from Stitch and will no longer function.
Migrate to the latest version of PostgreSQL (v1) today to continue replicating data.
Facebook Ads (v1) integrations: Use Batch API for adcreative table
We’ve updated the adcreative table in the Facebook Ads (v1) integration to use Facebook’s Batch API. This change was made to prevent errors resulting from requesting too much data.
Google BigQuery destination in open beta
We’ve built a new Google BigQuery destination from the ground up to address feedback from our customers and take advantage of new features on the platform, including the ability to upsert data.
Some notable improvements include:
-
The ability to choose between append only and upsert loading behavior
-
Authentication using your own Google Service Account
It’s available now - check it out!
MongoDB integration: New version (v1)
A new version (v1) of our MongoDB integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from MongoDB to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- User-facing Extraction Logs
- Field selection/exclusion using Projection Queries
- Support for logical replication via OpLog and Full Table Replication
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
Get started today by creating a new MongoDB integration or learn more in the updated documentation.
PostgreSQL (v1) integrations: Correctly type BIGINT[] data for Log-based Incremental Replication
Previously, Log-based Incremental Replication was incorrectly typing data types of INT8[] as STRING during data type conversion. This has been corrected.
Facebook Ads (v1) API upgrade to v4.0
The Facebook Ads integration now replicates data using version 4.0 of the Facebook Marketing API. For more details, view the Facebook API changelog.
New integration: Deputy
Deputy is a cloud-based workforce management and scheduling platform designed to help companies organize, track, and manage their teams. Our new Deputy integration enables you to extract all of your Deputy resources from a Deputy account.
Get started by creating a new Deputy integration or learning more in our documentation.
JIRA (v1) improvement: Added support for inactive users
The JIRA integration can now replicate inactive users into the users table.
To determine the status of a user, use the active field. For example: The following query will only return active users:
SELECT *
FROM jira.users
WHERE active = TRUE
MySQL (v1) integrations: Fix composite Primary Key sorting for Full Table Replication
Previously, the method used to bookmark Stitch’s place while replicating tables with composite Primary Keys resulted in some records being skipped. We’ve updated the query the integration uses to properly account for composite keys, ensuring replication will resume in the correct place.
Opt out of error notification emails
You can now opt out of system notification emails, freeing up inbox space and keeping your team on track. We’ll still let you know in-app if we run into any issues replicating data and via email for any billing information.
Check out the docs for more info.
PostgreSQL (v15-10-2015) deprecation
The v15-10-2015 version of our PostgreSQL integration has been deprecated. As of today, this version of the PostgreSQL integration is no longer formally supported.
While connections using v15-10-2015 will continue to run, this version will be sunset in the future. Migrate to the latest version of PostgreSQL (v1) today to prevent possible disruptions.
MySQL (v15-10-2015) sunset
The v version of our MySQL integration has been sunset. As of today, this version of the MySQL integration has been removed from Stitch and will no longer function.
Migrate to the latest version of MySQL (v1) today to continue replicating data.
Salesforce (v1) integrations: Remove SiteDetail object
We’ve determined that the SiteDetail object is incompatible with the Salesforce integration’s current method of querying, and as a result have removed it from the integration.
Refer to the tap repository for more info.
Salesforce (v1) integrations: Convert integer zero values to prevent schema violations
Salesforce’s API occasionally returns integer fields with a value of 0.0, resulting in schema violation errors during Extraction. To prevent this error, the integration now converts 0.0 to 0 if the field can be an integer.
Recurly integration: New version (v1)
A new version (v1) of our Recurly integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Recurly to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
_prefixes from table names - New tables, including:
- User-facing Extraction Logs
- Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new Recurly integration or learn more in the updated documentation.
Facebook Ads (v1) integrations: New ads_insights data
We’ve added a new table to our Facebook Ads (v1) integration: ads_insights_dma
This table contains entries for each campaign/set/ad combination for each day, along with detailed statistics, segmented by DMA (Designated Market Area).
Learn more in our documentation.
API access and management features for Enterprise
Take programmatic control over your Stitch account using the [Connect API](https://www.stitchdata.com/docs/developers/stitch-connect/api Now, you can manage your API keys right in your Stitch account.
This feature is available for our Enterprise customers or you can try it out during a 14-day free trial. Check out the docs.
New integration: Help Scout
Help Scout offers a help desk invisible to customers, that helps companies deliver outstanding customer support. Our new Stitch Help Scout integration enables you to extract conversations, threads, customers, mailboxes, users, and more from a Help Scout account.
Get started by creating a new Help Scout integration or learning more in our documentation.
New integration: MailChimp
MailChimp is a marketing automation platform and an email marketing service. Our new MailChimp integration enables you to extract automations, campaigns, lists, members, email activities, and more from a MailChimp account.
Get started by creating a new MailChimp integration or learning more in our documentation.
Post-load web hooks released for Enterprise customers
Want to be notified when data is loaded into your Stitch destination? With our new notification feature, you can!
Post-load webhooks send a webhook to a configurable address each time data is loaded into your destination. This new feature enables you to prompt other systems and processes to act on the data loaded by Stitch.
It’s available for our Enterprise customers, and you can try it out during a 14-day free trial. Learn more in our docs.
Salesforce (v1) integrations: Remove Announcement object
We’ve determined that the Announcement object is incompatible with the Salesforce integration’s current method of querying, and as a result have removed it from the integration.
Refer to the tap repository for more info.
Microsoft SQL Server integration: New version (v1)
A new version (v1) of our Microsoft SQL Server integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Microsoft SQL Server databases to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Logical Replication support via SQL Server Change Tracking
- User-facing Extraction Logs
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
Get started today by creating a new Microsoft SQL Server integration or learn more in the updated documentation.
New integration: LivePerson
LivePerson provides tools for online messaging, marketing, and analytics. The new Stitch LivePerson integration enables you to extract agent activity, groups, statuses, enagements, messages, users, and more from a LivePerson account.
Get started by creating a new LivePerson integration or learning more in our documentation.
New integration: Asana
Asana is a web and mobile application designed to help teams organize, track, and manage their work. The Stitch Asana integration will ETL Asana data to your destination, giving you access to raw project data, without the headache of writing and maintaining ETL scripts. Our new Stitch Asana integration enables you to extract projects, tags, tasks, users, workspaces from an Asana account.
Get started by creating a new Asana integration or learning more in our documentation.
New integration: Intacct
Intacct is an accounting and financial management software for the digital era. Our new Intacct integration enables you to extract core objects via the Intacct Data Delivery Service.
Get started by creating a new Intacct integration or learning more in our documentation.
Notification extensions for Enterprise
Enterprise clients can now save time by integrating Stitch monitoring and notification with the system they use to monitor the rest of their infrastructure. For example:
- Integrate with external monitoring systems like PagerDuty or Datadog
- Post updates to Slack
- Trigger other apps using Zapier
Learn more about notification extensibility here.
Advanced (cron) scheduling for Enterprise
Enterprise users can now specify granular start times for extraction jobs via cron scheduling. You can use this new feature to manage destination usage and Stitch row volumes.
This feature is available for our Enterprise customers and you can try it out during a 14-day free trial. Learn more about cron scheduling by reading the documentation.
New Stripe (v1) table: Disputes
Users now have the ability to replicate dispute data through the disputes table in Stripe (v1) integrations.
Facebook Ads (v1) API upgrade to v3.3
The Facebook Ads integration now replicates data using version 3.3 of the Facebook Marketing API.
NetSuite integration: New version (v1)
A new version (v1) of our NetSuite integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from NetSuite to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
netsuite_prefixes from table names - token based authentication
- Optimizations to API concurrency during discovery of tables/fields
- Utilization of an updated WSDL for a more complete set of tables/fields
- Field selection
Get started today by creating a new NetSuite integration or learn more in the updated documentation.
Start and Stop Extractions on demand
We’ve renamed the Extraction Logs page to simply Extractions.
We’ve also added new buttons to Run Extraction Now and Stop Extraction for those times when you need a little more control over when Stitch extracts data from your data sources.
Facebook Ads (v1) integrations: Workaround relevance_score deprecation
Due to Facebook prematurely deprecating relevance_score in their API, we’ve added logging to notify you should this field cause an error during replication:
Due to a bug with Facebook prematurely deprecating 'relevance_score' that is not affecting all tap-facebook users in the same way, you need to deselect `relevance_score` from your Insights export. For further information, please see this Facebook bug report thread: https://developers.facebook.com/support/bugs/2489592517771422
Should you encounter this error in Stitch, de-select the relevance_score field from any ads_insights_* tables you have set to replicate.
JIRA integration: New version (v1)
A new version (v1) of our JIRA integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from JIRA to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
jira_prefixes from table names - New tables, including:
- issues, changelog, and transitions are now top-level tables
- roles (formerly
jira_project_roles) - worklogs
- JIRA Cloud accounts now use an API token instead of user/password authentication
- User-facing Extraction Logs
- Table and field selection
- Run and stop Extraction on demand functionality
- Enhanced schema validation
Get started today by creating a new JIRA integration or learn more in the updated documentation.
MySQL (v1) integrations: Allow non-auto-incrementing Primary Keys for Full Table
Interruptible Full Table Replication now supports non-auto-incrementing Primary Keys!
Previously, this integration would only resume Full Table Replication if a table’s Primary Keys were auto-incrementing.
We’ve updated this feature to allow tables with non-auto-incrementing Primary Keys to be resumable if interrupted. Tables must have Primary Keys with one of the following data types to be interruptible if Full Table Replication is used:
BIGINTDATEDATETIMECHARINTMEDIUMINTSMALLINTTIMETIMESTAMPTINYINTVARCHAR
Salesforce (v1) integrations: Remove *ChangeEvent tables
We’ve determined that *ChangeEvent tables aren’t queryable via the Salesforce REST or Bulk APIs, and have removed them from the integration. Refer to the tap repository for more info.
Amazon Redshift (v2) destination transaction optimization
We have split DDL statements like ALTER table commands into their own transaction in Amazon Redshift destinations to minimize the length of time that tables are locked.
Microsoft Azure SQL Data Warehouse destination leaving open beta
Our Microsoft Azure Synapse Analytics destination has left open beta and is now generally available! Check out the press release or the docs for more info.
New integration: Responsys
Responsys enables marketing teams to manage and orchestrate all interactions with their customers across email, mobile, social, display, and the web. Stitch’s new Responsys integration extracts event data feeds, lists, audiences, and more from your configured Responsys Connect exports.
Get started by creating a new Responsys integration or learning more in our documentation.
New integration: Typeform
Typeform can help you build conversational forms, surveys, quizzes, landing pages, and more. The new Stitch Typeform integration extracts questions, landings and answers for the forms you care about the most. Choose the granularity you need by selecting between an hourly or daily breakdown of your data.
Get started by creating a new Typeform integration or learning more in our documentation.
New integration: Front
Front lets you manage all of your communication channels — email, social media, chat, SMS — in one place, and helps your team collaborate around every message. With the new Stitch integration, you can extract team member statistics related to conversations, messages, reaction times and more. Choose the granularity you need by selecting between an hourly or daily breakdown of your data.
Get started by creating a new Front integration or learning more in our documentation.
Stripe integration: New version (v1)
A new version (v) of our Stripe integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Stripe to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
stripe_prefixes from table names - New and improved tables, including:
- invoice_line_items
- subscription_items
- subscription_line_items
- The
transfer_transactionstable has been replaced by payouts
- User-facing Extraction Logs
- Table and field selection
- Availability via the Stitch Connect API
Get started today by creating a new Stripe integration or learn more in the updated documentation.
Shopify integration: New version (v1)
A new version (v1) of our Shopify integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Shopify to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- A few table changes and improvements:
- The collects and order_refunds tables now use Key-based Incremental Replication
- We’ve renamed
checkoutsto abandoned_checkouts to clarify the table’s available data - Product and customer metadata is now available! Track the products, customers, and metafields tables to replicate this data
- Optimized methods for retrieving Shopify data
- Optimized use of Shopify API quota for extraction
- User-facing Extraction Logs
- Table and field selection
- Availability via the Stitch Connect API
Get started today by creating a new Shopify integration or learn more in the updated documentation.
PostgreSQL (v1) integrations: BIGINT array support
PostgreSQL (v1) integrations now support arrays of BIGINTs.
Google BigQuery (v1) destinations: Additional region support
Google BigQuery has begun adding additional region support (beyond the US and EU) for their users, and we’ve just made these new regions available in Stitch for Google BigQuery (1) destinations. Stitch customers can now use Stitch with Google BigQuery instances in Tokyo, London, Singapore and Sydney.
Salesforce (v1) integrations: Correct date chunking for Bulk API replication
For Salesforce integrations using the Bulk API, when a query to the API times out, Stitch would cut the requested date range in half and re-try the request. However, after replicating the records, the integration wouldn’t attempt to replicate the second half of the original window, resulting in missed records.
Because the integration only updates Replication Keys when records are extracted, Replication Keys wouldn’t advance if records weren’t received in the first half of the date range. This meant that the integration wouldn’t ever try to replicate records in the second half of the date range.
This fix adds a check to see if the date range was chunked, and if so, queries the second half of the chunked range and extracts records, if any exist.
Google BigQuery (v1) destinations: Partitioned table support
Stitch now supports loading to Google BigQuery partitioned tables and ingestion-time partitioned tables with and without clustering. We’ve added instructions to our docs for converting existing tables into partitioned and clustered tables.
Microsoft Azure SQL Data Warehouse (v1) destination now in open beta!
If you’ve been waiting to get Stitch hooked up to Microsoft Azure Synapse Analytics, good news! As of today, this destination is available for any customer to use. Learn more in the new docs.
Google BigQuery (v1) destinations: NUMERIC data type support
We’ve added support for the NUMERIC data type in Google BigQuery destinations. Numeric data will be loaded into NUMERIC columns going forward, rather than columns with the floating point data type.
Facebook Ads (v1) integrations: API upgrade to v3.2
We have updated the Facebook Ads integration to use the latest version of the Facebook Marketing API - version 3.2.
As part of this update, Facebook has deprecated many values for cost_per_action_type to simplify reporting and support reporting based on their new eight standard events. Additionally, the total_action_value field has been deprecated and removed from all ads_insights tables.
PostgreSQL (v1) destinations: SSL certificate verification support
Users can now provide a certificate for their Amazon Aurora PostgreSQL destination that will be used to verify the identity of their server.
Pipedrive (v1) integration: Removed goals table
As per an update to the Pipedrive API, the goals table has been removed from the Stitch integration. See more about the available Pipedrive data in our documentation.
Salesforce (v1) integrations: BackgroundOperationResult is now Full Table
We’ve determined that the BackgroundOperationResult object doesn’t support ordering by CreatedDate, meaning that Stitch can’t reliably replicate this data incrementally. This table now has a forced Replication Method of Full Table.
MySQL (v1) integrations: Interruptible Full Table replication
Fullly replicating a table is now “interruptible,” meaning that, if the table uses auto-incrementing Primary Keys, replication for the table can span multiple replication jobs.
Previously, a table using Full Table had to be fully replicated in a single job. If the job was interrupted for any reason, Stitch would replicate the table from the beginning during the next job.
Now, if a replication job is interrupted for a MySQL (v1) integration, tables using Full Table Replication that have auto-incrementing Primary Keys will resume replication from the last replicated record instead of re-replicating the entire table.
Bing Ads integration: New version (v2)
A new version (v2) of our Bing Ads integration is now available! This version takes advantage of the latest Bing Ads API, version 12.
Here’s a high-level look at the updates to our integration:
-
Support for multi-user credentials: The new integration allow for extracting data where you use one Microsoft account and manage accounts across different customers.
-
Column restrictions: Bing now prevents the extraction of reports with invalid field combinations. Stitch will automatically show these exclusions within the field selection interface when setting up your reports. Refer to Bing’s documentation for a full list of column restrictions.
-
Schema updates: The following changes have been made to table schemas:
New integration: Campaign Monitor
Stitch’s new Campaign Monitor integration will extract your lists, campaigns, and campaign activity to power all of your email marketing analyses. Create a Campaign Monitor integration today and load your historical data for free.
Get started by creating a new Campaign Monitor integration or learning more in our documentation.
PostgreSQL (v1) integrations: Fix selected-by-default behavior
We’ve fixed an issue with PostgreSQL (v1) integrations where columns marked as selected-by-default will now be replicated unless explicitly deselected.
PostgreSQL (v1) integrations: Primary Key discovery
Previously, Primary Keys weren’t detected during Discovery if other indices or unique constraints existed on the column. This has been corrected.
New integration: Harvest Forecast
Harvest Forecast is a fast and simple way to schedule your team across projects. With Stitch’s new integration, you can extract core object such as assignments, clients, milestones, projects and people to your Stitch destination. Combine your project data with your other sources by adding a new integration today. Learn more in our documentation.
New integration: Close.io
A new Close.io integration is now available! This integration replicates your activities, leads, tasks, users and the raw event log from your Close.io account. Create a Close.io integration today and empower your sales team to make better data driven decisions. Learn more in our documentation.
Harvest integration: New version (v2)
A new version (v2) of our Harvest integration is now available!
Changes in this version include:
- Upgrading to V2 of the Harvest API
- Many new tables
- Schema modifications to align with the Harvest API
- The
peopletable was renamed tousers, as per new Harvest API endpoints
Full details can be found on the pull request against the open sourced integration here. Stitch docs for the version 2 of the Harvest integration can be found here.
Salesforce (v1) integrations: Fix for OpportunityFieldHistory parent
Previously, OpportunityFieldHistory exports failed due to a function in the Salesforce integration incorrectly returning OpportunityField as the parent. This fix adds a check for the FieldHistory suffix, ensuring that the parent is correctly returned as Opportunity.
New integration: Amplitude
A new Amplitude integration is now available! This integration extracts event and user data from your Amplitude projects. Amplitude is an analytics service for modern product teams to understand user behavior, ship the right features fast, and drive business outcomes. Our integration enables you to extract raw data from the Amplitude Query product and combine it with all the data in your Stitch destination.
Get started by creating a new Amplitude integration or learning more in our documentation.
PostgreSQL (v1) integrations: Include schema name in destination table names
We’ve added a new setting to PostgreSQL (v1) integrations:

When checked, Stitch will include schema names from the source database in the destination table name when the table is created. For example: <source_schema_name>__<table_name>
Stitch loads all selected replicated tables to a single schema, preserving only the table name. If two tables canonicalize to the same name - even if they’re in different source databases or schemas - name collision errors can arise. Checking this setting can prevent these issues.
Note: This setting can not be changed after the integration is saved. Additionally, this setting may create table names that exceed your destination’s limits.
New integration: Xero
A new Xero integration is now available! With the new integration, Stitch will replicate your core Xero objects including bank transactions, contacts, invoices, journal entries, payments, and more to your Stitch destination.
Get started by creating a new Xero integration or learning more in our documentation.
PostgreSQL (v1) integrations: Expanded replication slot support
Stitch now supports Log-based Incremental Replication across multiple databases in a single PostgreSQL cluster. Previously, Stitch supported one replication slot per integration and required it to be named stitch. Now, Stitch will look for the replication slot you define before falling back to stitch.
New integration: Google (DoubleClick) Campaign Manager
Stitch has a new integration with Google Campaign Manager (formerly DoubleClick Campaign Manager). After you select Campaign Manager reports, Stitch will run them and replicate the results to your Stitch destination.
Get started by creating a new Campaign Manager integration or learning more in our documentation.
New integration: Yotpo
A new Yotpo integration is now available! Yotpo generates social reviews, ratings, and other user-generated content for eCommerce websites.
Get started by creating a new Yotpo integration or learning more in our documentation.
Google AdWords (v1) integrations: API upgrade to v201806
The Google AdWords integration has been updated to use v201806 of the AdWords API, from v201802.
Notable changes include:
-
Ad Groups: The
AdGroupTypeenum valueSHOPPING_UNIVERSAL_ADSwas renamed toSHOPPING_GOAL_OPTIMIZED_ADS. -
Ad Group Performance Report: The
AdGroupTypefield will now return a value of“Shopping - Goal-optimized”where it previously returned“Shopping - Universal”, and the corresponding enum value changed fromSHOPPING_UNIVERSAL_ADStoSHOPPING_GOAL_OPTIMIZED_ADS.
PostgreSQL (v1) integrations: PG 10 now supported for Logical Replication
Stitch now supports PostgreSQL 10 when using Log-based Incremental Replication. Previously, Stitch supported PostgreSQL 9.4.x - 9.9.x.
New integration: Amazon S3 CSV
A new Amazon S3 CSV integration is now available!
This integration can connect to your S3 bucket and replicate CSV files to your Stitch destination. Some highlights of this new integration include:
- Replication of data from CSV files stored in your S3 buckets
- Support for incremental updates based on new or modified CSV files
- Column selection for choosing which columns you want to extract from your CSV files
- Automatic inference of data types and the ability to explicitly specify datetime fields
Get started by creating a new Amazon S3 CSV integration or learning more in our documentation.
Zendesk integration: New version (v1)
A new version (v1) of our Zendesk Support integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Zendesk Support to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- User-facing Extraction Logs
- Table and field selection
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new Zendesk Support integration or learn more in the updated documentation.
PostgreSQL integration: New version (v1)
A new version (v1) of our PostgreSQL integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from PostgreSQL to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Logical replication support, which allows you to replicate data from database binary logs, including hard deletes, without the use of a Replication Key
- User-facing Extraction Logs
- Table and field selection
- Enhanced scheduling options
- Run and stop Extraction on demand functionality
- Availability via the Stitch Connect API
- Enhanced schema validation
Get started today by creating a new PostgreSQL integration or learn more in the updated documentation.
Facebook Ads (v1) integrations: Field deprecation
Facebook has deprecated the following fields, meaning they are no longer available for selection or retrieval via Facebook’s API:
call_to_action_clickscost_per_total_actionsocial_reachsocial_impressionssocial_clicksunique_social_clickstoday_spendtotal_actionstotal_unique_actions
In addition, several types of metrics have been deprecated. Note: The fields are still available, but the types listed below are not:
actionsfield:mention,tab_viewaction_valuesfield:app_custom_eventcost_per_action_typefield:mention,tab_viewcanvas_avg_view_percentage_per_componentfield:canvas_view
Salesforce (v1) integrations: Add suffix to parent tables ending in __
Previously, Salesforce integrations attempted to perform PK (Primary Key) chunking for custom tables using an incorrect parent table name. This fix now appends c to parent tables ending in __, ensuring chunking is performed correctly.
New community integrations available
Thanks to the contributions of the Singer community, Stitch has five new integrations available for all customers to use:
-
Bronto (v1): An email marketing platform for ecommerce
-
FullStory (v1): A tool that offers high-fidelity session playback
-
Listrak (v1): A marketing platform for engaging shoppers across all channels
-
Quick Base (v1): A platform for developers to build, customize and connect scalable, secure cloud applications
-
SendGrid Core (v1): A platform for delivering transactional and marketing emails
All of these integrations are built on the Singer open source project and take advantage of Stitch’s secure and scalable infrastructure.
Get started by adding a new integration today or learning more in our documentation.
Marketo integration: New version (v2)
A new version (v2) of our Marketo integration is now available! Major changes include:
- Activity selection – Each Marketo activity type is now its own table, allowing you to replicate just the ones you care about the most.
- Replication of campaigns and programs – These objects are now available for replication to your destination.
- Column selection – Just as with tables, we’ll only replicate the columns that you want.
- Improved efficiency – The integration now uses Marketo Bulk API, which allows us to more efficiently replicate large amounts of data. Review our documentation for more details.
Learn more about the integration and these features in our Marketo integration documentation.
Amazon S3 (v1) destination leaving open beta
Our Amazon S3 destination has left open beta and is now generally available! Check it out today to get your source data delivered to your S3 bucket in either JSON or CSV. Check out the docs for more info.
New integration: GitHub
A new GitHub integration is now available!
This integration lets you extract data from any GitHub repository. You can choose from the following tables to replicate to your destination:
assigneescollaboratorscommitsissuespull_requestsreviewsstargazers
Create a new integration today with seven days of free historical data. Learn more in our documentation.
Zuora integration: New version (v1)
A new version (v1) of our Zuora integration is now available!
We’ve worked hard to ensure this new integration is the best way to extract data from Zuora to your Stitch destination. The new integration, based on the Singer standard, includes many new features such as:
- Removal of
zuora_prefixes from table names - Expanded table and field availability
- Choice of Zuora API, allowing you to choose the API that best fits your needs
- Replication of deleted records when using the AQuA API
- Table and field selection
- Enhanced schema validation
Get started today by creating a new Zuora integration or learn more in the updated documentation.
HubSpot integration: New version (v2)
A new version (v2) of our HubSpot integration is now available! Major changes include:
- Column-level selection
- More comprehensive data typing on custom properties
- Inclusion of all form submissions for
contacts– Older versions only replicated the newest form submissions. Now you can extract a complete picture of your contact form submissions. - Improved updates of the
list_membershipstable - Several schema changes:
hubspot_contacts_by_companyhas been renamed tocontacts_by_company- The
isDeletedfields have been removed from thedealsandcompaniestables. The HubSpot API does not provide accurate values for this data, so we’ve removed it to prevent confusion and potential discrepancies. - The
keywordstable has been removed. HubSpot has deprecated the keywords feature of their product and API. Note: HubSpot has deprecated their Keywords tool as of June 1. - New counters added to
campaigns, including:deferred,unsubscribed,statuschange,bounce,mta_dropped,suppressed
Learn more about the integration and these features in our HubSpot integration documentation.
MySQL (v1) integrations: Binlog replication support
MySQL integrations can now use binlog replication to perform incremental replication in Stitch!
If you have binary logging enabled for your MySQL database, Stitch can now use it to help replicate your data. Log-based Incremental Replication allows for incremental replication of a table without a Replication Key and will capture and persist hard deletes.
This feature is now available as a Replication Method on the Table Settings of MySQL integrations. Check out the docs for more info.
Free historical data loads for all new integrations
All new integrations will replicate seven days of unlimited data without impacting your monthly quota. Get started by creating a new integration or learn more on our blog.
Time-based replication scheduling is now available!
Stitch customers now have some control over when extractions begin. This new feature allows users to “anchor” extraction start times to a specific time, ensuring Stitch is predictably replicating data when it’s most needed.
For example: Setting a six (6) hour replication with an anchor time of 12:00 PM would create this schedule:
- 12:00PM
- 06:00PM
- 12:00AM
- 06:00AM
Check out the docs for full details.
Amazon S3 (v1) destination now in open beta
Amazon S3 is now available in open beta as a Stitch destination. Highlights include support for both JSON and CSV formats and the ability to customize the S3 Object Keys to control how your data is stored.
Check out the docs for more info.
New integration: Bing Ads
A new Bing Ads integration is now available!
Stitch’s Bing Ads integration lets you replicate data from Microsoft’s search advertising platform to the Stitch destination of your choice.
A few highlights from the integration include:
- Replication from eight of the most popular Bing Ads reports
- Configurable fields in each of your selected reports
- Connection to multiple ads accounts in each Stitch integration
- [Append-Only loading behavior](https://www.stitchdata.com/docs/replication/loading/understanding-loading-behavior, enabling you to see report changes over time
- A new
_sdc_report_datefield, allowing you to see when data was retrieved from Bing Ads
Get started by creating a new Bing Ads integration or learning more in our documentation.
New billing option: Annual plans
Discounted annual plans are now available! Signing up for a year of Stitch will net customers 2 months free. You can change to an annual plan at any time.
Facebook Ads (v1) integrations: API upgrade to v2.11
We’ve updated our Facebook Ads integration to use the newest version of the Facebook Marketing API - version 2.11.
In addition, we’ve made the following improvements:
-
Configurable attribution window when creating or editing a Facebook Ads integration. Choose between
1,7or28days so that Stitch replicates historical data in alignment with the attribution window of your Facebook Ads account. -
A new table named
ads_insights_region. View your data by the region (such as state or province) where people live or were located when they saw your ads, depending on how you set your location targeting. -
Removed the
video_15_sec_watched_actionsattribute from relevant tables. Facebook deprecated this attribute in the 2.11 version of their API.
New destination: data.world
A new data.world destination is now available!
data.world helps you host and share your data, collaborate with your team, and capture context and conclusions as you work. We’ve partnered with them to allow you to replicate all your sources into your data.world account.
Check out the docs for more info.
Introducing Stitch Connect
We’ve just released Stitch Connect, a toolkit that enables developers to integrate a data pipeline with their own platforms behind the scenes as a seamless part of their infrastructure.
Stitch Connect comprises a JavaScript user interface and an API that lets developers programmatically create and access Stitch client accounts and configure source and destination connections.
Interested in seeing how it could work with your application? Check out the docs or get in touch.
Salesforce (v1): ContentFolderItem is no longer supported
We’ve determined that the ContentFolderItem object is incompatible with Stitch’s querying strategy, and as a result is no longer available for replication via the Salesforce REST API option.
Google AdWords (v1) integrations: API upgrade to v2.11
We’ve updated our Google AdWords integration to use the newest Adwords API - version v201802.
Additionally, we’ve made the following chanegs:
-
In the
adstable, thepolicyTopicEvidencesobject in thepolicySummary.policyTopicEntriesfield contains anevidenceTextfield. This field (evidenceText) has been renamed toevidenceTextListand is now a list. -
In the
ad_performance_reporttable, theImageAdUrlfield now returns the entire URL string -
In various reports:
- The
BidTypefield has been removed - The
EnhancedCpvEnabledfield has been removed from all reports. This field was used for experiments that are no longer active.
- The
See the AdWords API release notes for additional details.
Loading Reports are now available!
Loading Reports are now available!
A few months ago, we launched access to Extraction Logs for select integrations. Today, we’re releasing additional transparency for replication, this time on the loading end of things.
All Stitch users can now see:
- A breakdown of row counts by tables (and subtables) for each integration
- A timeline of loads for each table
- Select integrations (MySQL, Facebook, Salesforce and HubSpot to name a few) have latest data point and extraction time info per table
Check out the docs for more info.
Facebook Ads (v1) integrations: Include deleted ads, adsets, and campaigns
We’ve added a new setting for Facebook Ads (v1) integrations that enables you to replicate records for deleted ads, adsets, and campaigns:

When checked, Stitch will query for and extract data for deleted ads, adsets, and campaigns from your Facebook Ads account. Relevant records will be included in the ads, adcreatives, adsets, and campaigns tables, if selected for replication.
Learn more in our Facebook Ads integration documentation.
Salesforce (v1): Additional incompatible objects
We’ve found that the following objects are incompatible with Stitch’s querying strategy, and as a result are no longer available for replication:
LookedUpFromActivityAttachedContentNoteQuoteTemplateRichTextData
MySQL (v15-10-2015) deprecation
The v version of our MySQL integration has been deprecated. As of today, this version of the MySQL integration is no longer formally supported.
While connections using v will continue to run, this version will be sunset in the future. Migrate to the latest version of MySQL (v1) today to prevent possible disruptions.
Facebook Ads (v1) integrations: use_page_actor_override field deprecation
Due to issues with querying and a bug in Facebook’s API, we’re removing support for the adcreative.use_page_actor_override column. As a result, this column will no longer display in Stitch as available for replication.
Facebook Ads (v15-10-2015) integration: API upgrade to v2.9
We’ve updated the integration to use a new version of the Facebook API. This update also provides access to a new table (facebook_ads_insights_platform_and_device), which contains fields allowing you to compare insights between platforms such as Facebok, Instagram, and Messenger, and positions such as feeds, instant articles, and stories.
Facebook Ads (v15-10-2015) integration: Improved error handling
We’ve updated the error handling in the Facebook Ads integration to more aggressively retry when Insights jobs fail. As a result of this change, the error rate for this integration has been significantly reduced.
Introducing Stitch Community integrations
Introducing: Stitch Community integrations!
Just like other Singer taps, these integrations are able to be run in Stitch. Thanks to the success of the inger open source project and the contributions from the Singer community, we’re able to run these integrations on the Stitch infrastructure while being supported by the community rather than the Stitch team.
Like Stitch Certified integrations (built and maintained by the Stitch team), Stitch Community integrations offer a number of benefits:
- Running at scale on a reliable infrastructure
- Secure credential management
- Setup and configuration via the Stitch interface
- Configurable scheduling
- Automated notifications when something goes wrong
- Log exploration interface
- Access to all of the Stitch-supported destinations
The key difference is that Stitch provides commercial support for Certified integrations, but not for Community integrations. Commercial support is a guarantee that the Stitch team will fix bugs and adapt to new versions of third-party APIs.
For a full list of Stitch integrations - including both Certified and Community - refer to the docs.
Salesforce (v1): Primary Key (PK) chunking
We’ve implemented Salesforce’s Primary Key (PK) chunking feature into our integration.
If the integration is using the Bulk API and encounters a timeout error, Stitch will now re-try using the Sforce-Enable-PKChunking header in the API request. This approach ‘chunks’ data into small batches, allowing the integration to more efficiently extract large volumes of data.
Google AdWords integration: New version (v1)
A new version (v1) of our Google AdWords integration is now available!
A few highlights include:
- Utilizing the AdWords API to replicate the most popular Google AdWords reports to Stitch
- Configurable fields in each of your selected Google AdWords reports
- Connect multiple individual or MCC AdWords accounts in each Stitch integration
- Using a 30-day conversion/lookback window to update data over the past 30 days
- Loading report data using Append-Only loading with an
_sdc_report_datefield so that users know when data was retrieved from the AdWords API
Learn more about the new version in our documentation.
Salesforce (v1): Improved record type handling
We’ve added handling for several Salesforce record types:
bytecalculatedDataCategoryGroupReferencemasterRecord
Salesforce integration: New version (v1)
A new version (v1) of our Salesforce integration is now available! Major changes include:
- Choose between Salesforce Bulk or REST API
- Configure how much of your Salesforce API quota Stitch can use
- Connect to Salesforce Sandbox accounts
- Choose whether Stitch automatically replicates new fields
- Reset the Replication Key for individual Salesforce tables in Stitch
- Toggle between Incremental or ull Table Replication for tables
- Access the latest objects and fields from the newest version of the Salesforce API
- Removed
sf_prefix for tables for all newly created integrations
Learn more about the integration and these features in our Salesforce integration documentation.
Extraction logs now available!
Detailed Extraction Logs are now available for select integrations in Stitch. This new feature presents detailed information about the extraction process in these integrations, and lets you:
- Inspect, copy, and download extraction log files up to 50MB in size
- View historical logs over the past seven days
- Visualize how often extraction runs, how long it takes, and when it errors
- View logs for extraction jobs currently in progress
This feature is available for the following integrations:
-
Salesforce (v1): (v1 only)
We’ll be working over the coming weeks to bring these logs to the rest of our integrations. Check out the docs for more info on this new feature.
Facebook Ads (v1) integrations: Ads, AdSets, and Campaigns now replicate incrementally!
Big news: The following Facebook Ads integration tables, which previously replicated in full, now use Key-based Incremental Replication:
adsadsetscampaigns
These tables use updated_time as Replication Keys, ensuring you’re only replicating records that have been updated. You can learn more about these tables in our Facebook Ads integration documentation.
Facebook Ads (v1) integrations: AdLabel data is now available!
We’ve added the adlabels fields to the adsets and campaigns tables for our Facebook Ads (v1) integration.
Learn more in our documentation.
MySQL (v1) integrations: Primary Keys can't be an unsupported data type
Previously, this integration would allow columns with unsupported data types to be included in the Primary Keys (key_properties) for a table. This has been corrected.
New version (v1) of MySQL integration
A new version (v1) of our MySQL integration is now available!
Learn more about the integration and these features in our MySQL integration documentation.
Google BigQuery (v1) destination leaving open beta
Our Google BigQuery destination has left open beta and is now generally available! Check out the the docs for more info.
Facebook Ads integration: New version (v1)
A new (open-sourced!) version (v1) of our Facebook Ads integration is now available! This version, built from the ground up, supports field selection for increased control over what data you replicate through Stitch.
Learn more about the integration in our Facebook Ads integration documentation.
New integration: Autopilot
A new Autopilot integration is now available! Make your customer journeys take flight with data from Autopilot - now generally available as a Stitch source.
Get started by creating a new Autopilot integration or learning more in our documentation.
HubSpot integration: New version (v1)
A new (open-sourced!) version (v1) of our HubSpot integration is now available!
Major improvements include:
- Table selection
- Improved data typing
- Improved Primary Keys
- New tables:
hubspot_contacts_by_companyengagements
Open sourcing our integrations means more transparency into and flexibility around integration features. If you’d like to contribute to the HubSpot integration, you can check out the code here.
Learn more about the integration and these features in our HubSpot integration documentation.
Snowflake (v1) destination leaving open beta
Our Snowflake destination has left open beta and is now generally available! Snowflake is a SQL data warehouse built from the ground up for the cloud, designed with a patented new architecture to handle today’s and tomorrow’s data and analytics.
Check out the the docs for more info.
Replication scheduling change for non-database integrations
Non-database integrations now schedule replication by waiting the configured interval from the last time they were scheduled. This means that integrations with a daily schedule will run at the same time every day, and those with an hourly schedule will run at the same number of minutes past every hour. With the change, all integrations now use this scheduling logic.
Refer to the docs for more info and examples.
Change your destination!
Not happy with where your data is headed? Now you can do something about it!

Customers can now change destination types right in their account. Check out the docs for more info.
Lots of integrations leaving beta
Like baby birds leaving the nest, baby bears leaving their dens, or baby platipi leaving… whereever it is that platypi live… so too have many of our integrations recently left open beta.
Here’s the list:

Snowflake (v1) destination now in open beta!
If you’ve been waiting to get Stitch hooked up to Snowflake, wait no longer! We’re happy to announce that as of today, Snowflake has entered open beta and is available for any customer to use.
Snowflake (v1) destination now in closed beta!
Been waiting for Stitch to support Snowflake? Good news - Snowflake as a destination has just entered closed beta and testing has already begun! If you’re interested in getting on the list, add your email address here and we’ll let you know as we add more testers.
Improved UI speed
We’ve deployed some efficiency improvements to a key backend service that has led to a (in some cases significant) speed up of the Stitch user interface.
PostgreSQL (v1) destination leaving open beta
Our Amazon Aurora PostgreSQL destination has left open beta and is now generally available! Check out the the docs for more info.
Google BigQuery (v1) destination: Data type incompatibilities fix
We’ve improved the way Stitch loads data into Google BigQuery destinations. This update, already in production, fixes data type incompatibilities that were preventing certain tables from loading data into Google BigQuery datasets.
New integrations: Harvest, Taboola, and Urban Airship
Stitch is pleased to announce the release of several new integrations, which are now available to all customers:
MongoDB (v11-01-2016) integrations: Support for Mongo 3.4 and SSL connections
Time marches on, as do versions. Today, we’re happy to announce support for the latest version of MongoDB, version 3.4. Additionally, Stitch now supports connecting securely to Mongo instances using SSL.
New and improved Stitch Docs
Stitch is excited to relaunch a redesigned version of our extensive documentation, including a brand new Getting Started guide and a guide on picking the right destination for you.
Google Cloud SQL PostgreSQL Support
We’re excited to report that Stitch supports the recently announced PostgreSQL flavor of the the Google CloudSQL service. It’s available as both an input integration AND a destination - a dual threat!
Support for Singer Taps - 10 new integrations!
Stitch now has built-in support for Singer Taps, the data extraction component of the the just launched simple, composable, open source ETL Singer project. This exciting new standard will make getting data out of any source and into Stitch (or elsewhere) simpler and more straightforward.
To learn more about Singer, check out the launch blog post.
By supporting this standard, Stitch now supports these integrations:
Google Analytics (v14-09-2016) integrations: New default Replication Frequency
The default Replication Frequency for Google Analytics integrations is now 6 hours. Want to replicate your data at a faster rate? Learn more in our docs.
New integration: Branch
Are you using Branch for deep linking in your mobile app? Now you can replicate event data from your Branch account to your destination and analyze app installs and engagement.
Get started by creating a new Branch integration or learning more in our documentation.
Stitch Webhooks and 14 new integrations
Introducing: Stitch Webhooks!
Stitch Webhooks is a configurable incoming webhook integration that replicates data from hundreds of webhook APIs directly to Stitch.
Additionally, we’ve added 14 new integrations to Stitch, powered by webhooks, as great examples of what you can replicate across different types of applications:
Enhanced integration replication stats
Ever wondered where your data was after Stitch pulled it from the source but hadn’t arrived in your destination yet?
When the next replication job will start?
How many rows you’ve loaded today?
This information (and more) is now available in Stitch: Just click on any individual integration to experience this… experience. Check out the docs for more info.
Support for replicating database views
With the new year fast approaching, the Stitch engineers wanted to slip in a last update or two to the product before the ball drops. Customers can now see and replicate views for database integrations in Stitch - just pick a Primary Key and Replication Method. Enjoy!
Logging for rejected records
Occasionally, Stitch encounters data that it can’t load into a destination for a variety of reasons: Dates that fall out of range, table names that are too long, etc.
Stitch now logs these records into a special table (_sdc_rejected) for each integration. Each rejected record includes the reason for the rejection and as much data from the original record as can fit.
Learn more in the docs.
In-app notifications now available
When things go wrong, as they occasionally do, Stitch sends an email notification about this issue. Now, those notifications are available inside the Stitch interface as well. Just click on the Notifications tab at the top of the page to see your active notifications.
Google BigQuery (v1) and PostgreSQL (v1) destinations now in open beta!
If Amazon Redshift isn’t the right destination for you, then we’ve got you covered. Our Google BigQuery and PostgreSQL destinations are now in open beta - and you can set them up in Stitch today! Both are available during destination selection in the onboarding process.
To learn more about how Stitch loads data into these destinations, check out the docs for Google BigQuery and PostgreSQL destinations.
Re-using schema names from deleted integrations
Delete an integration, and still attached to the schema name that went with it? Now you can re-use schema names from deleted integrations when you set up new ones.
Reset Replication Keys for individual tables in database integrations
Hot off the heels of support for resetting the Replication Keys for an entire database integration, Stitch now offers the ability to do it on a per table basis. Head down to the Table Settings in a database integration for an individual table and you’ll see the new button.
PostgreSQL destination (v1) in closed beta
Longing to get your data into Amazon Aurora PostgreSQL instead of Amazon Redshift?
Good news, everyone!
Amazon Aurora PostgreSQL as a Stitch destination is now in closed beta! Sign up today if you are interested in the beta and we’ll add you to the waiting list. In the mean time, learn more about this destination in the docs.
LONGNVARCHAR data type support
Up until now, Stitch supported VARCHAR, NVARCHAR, and LONGVARCHAR. Today we’ve added support for the crazy uncle of the VARCHAR family, LONGNVARCHAR!
Just a note: If you have existing database integrations that have this data type, you’ll need to go in and specifically track it. Any new integrations will automatically track this data type.
New destination: Panoply.io
A new Panoply destination is now available!
Interested in Amazon Redshift but don’t want the hassle of maintaining an Amazon Web Services account? Exciting news - Stitch has partnered with Panoply to bring their managed data warehouse solution to our users - including a free tier with up to 10 million rows per month!
Get started by creating a new Panoply destination or learning more in our documentation.
Salesforce (v15-10-2015) integrations: Field selection support
Do objects in your Salesforce have a lot of fields? Do you only care about a few of them? Don’t you wish you could only track what you want?
Well, now you can! Starting today, you can select which fields to replicate from your Salesforce objects, giving you more control to keep your destination clean and simple. Learn more in the docs.
Close.io integration now in open beta
A new Close.io is now available!
The new integration will replicate all of your leads and activities to your warehouse, allowing you to analyze your sales cycle and always be closing.
Get started by creating a new Close.io integration or learning more in our documentation.
Google BigQuery (v1) destination in closed beta
Excited about Google BigQuery? We’ve got some big news for you!
Our Google BigQuery destination is now in closed beta. Sign up if you’re interested in joining the beta to start sending your data to Google BigQuery. In the mean time, learn more about this destination in the docs.
New integration bonanza!
Lots of integration related news today. Ready? Here we go:
-
Google Analytics (v14-09-2016): We’ve opened up the beta for our new Google Analytics integration. This new integration allows you to create custom datasets using Google Analytics’s metrics and dimensions.
-
Intercom (v02-02-2016): Intercom is leaving beta
-
Pardot (v15-10-2015): Pardot is leaving beta
-
Recurly (v14-09-2016): Recurly is leaving beta
-
Segment (v1): Segment is leaving beta
-
Trello (v15-12-2015): Trello is leaving beta
Get out there and start moving some data.
MongoDB (v11-01-2016) integrations: Replication Keys modification support
Ever select the wrong Replication Key for a MongoDB integration when setting up Incremental Replication? If so, you’ll know that it’s a headache to change it.
Now, you can easily change it to the correct field within the Stitch app. Note that doing so will force a full re-replication of the table, to ensure all data is replicated using the correct Replication Key.
Zendesk (v15-10-2015) integrations: New group membership table
The Zendesk Support integration now includes a zendesk_group_memberships table, which contains information about the groups your Zendesk Support agents are members of. Fields in this table include:
- Group membership ID (
id) - URL
- Name
- Deletion flag
created_atupdated_at
NetSuite (v10-15-2015) integrations: Deleted record support
The NetSuite integration now includes a table called netsuite_deleted which contains a row for every deleted record that supports deletes.
Accounting for deleted records is especially important if you’re performing any sort of aggregate function, such as totaling invoices or balancing your books.
Learn more about utilizing the NetSuite deletion log in our [docs](https://www.stitchdata.com/docs/integrations/saas/netsuite-suitetalk/v10-15-2015#using-netsuite-deleted.
Reset Replication Keys for database integrations
Need to completely re-replicate all incrementally replicated tables in a database integration? Now you can(!) via the Integration Settings page on any MySQL, PostgreSQL, Microsoft SQL Server, or MongoDB integration. Take care though - the re-replicated rows count towards your monthly caps.
Amazon Redshift (v2) destination: Fix boolean precision
This release ensures precision for boolean data types, specifically that false values are accurately displayed as false (instead of null) in Amazon Redshift.
Amazon Redshift (v2) destination: Increase decimal precision and scale
This release increases the precision and scale of decimal types in Amazon Redshift, changing from the Amazon Redshift default of DECIMAL(18,0) to DECIMAL(38,6).
Change an integration's display name
Don’t like what you named your integration? Now you can change it!
Integration names can be edited on the Settings page for each respective integration. Note: Changing an integration’s name won’t change the name of the schema in your destination.
Learn more in the docs.
PostgreSQL (v15-10-2015) integrations: ARRAY and JSONB data type support
All PostgreSQL fields of type JSONB and ARRAY may now be tracked from the Integrations page. These fields will be converted to strings in Amazon Redshift.
Introducing: This Changelog
We added a changelog to stitchdata.com to make it even easier to learn about Stitch product updates. Very meta.
Getting Stitched
Everything that used to be called RJMetrics Pipeline is now called Stitch. Basically, a big s/RJMetrics Pipeline/Stitch/g on our codebase.
Amazon Redshift destination: New version (v2)
Now 50% Redshiftier, along with these improvements:
- Faster loading for high volume data streams
- Transactional upserts
- NO MORE VIEWS! Data is materialized into tables directly in the target schema, and these tables are never dropped
Learn more in the docs.