Reference documentation for Stitch’s Amazon S3 destination, including info about Stitch features, replication, and transformations.
This guide serves as a reference for version 1 of Stitch’s Amazon S3 destination.
Details and features
Stitch features
High-level details about Stitch’s implementation of Amazon S3, such as supported connection methods, availability on Stitch plans, etc.
| Release status |
Released |
| Stitch plan availability |
All Stitch plans |
| Stitch supported regions |
Operating regions determine the location of the resources Stitch uses to process your data. Learn more. |
| Supported versions |
Not applicable |
| Connect API availability |
Supported
This version of the Amazon S3 destination can be created and managed using Stitch’s Connect API. Learn more. |
| SSH connections |
Not applicable |
| SSL connections |
Not applicable |
| VPN connections |
Not applicable |
| Static IP addresses |
Supported
This version of the Amazon S3 destination has static IP addresses that can be whitelisted. |
| Default loading behavior |
Append-Only |
| Nested structure support |
Depends on data storage format (CSV or JSON) |
Destination details
Details about the destination, including object names, table and column limits, reserved keywords, etc.
Note: Exceeding the limits noted below will result in loading errors or rejected data.
Amazon S3 pricing
Amazon S3 pricing is based on two factors: The amount of data stored in and location (region) of your Amazon S3 bucket.
To learn more about pricing, refer to Amazon’s S3 pricing page. Note: Remember to select the correct region to view accurate pricing.
Replication
Replication process overview
A Stitch replication job consists of three stages:
Step 1: Data extraction
Stitch requests and extracts data from a data source. Refer to the System overview guide for a more detailed explanation of the Extraction phase.
Step 2: Preparation
During this phase, the extracted data is buffered in Stitch’s durable, highly available internal data pipeline and readied for loading. Refer to the System overview guide for a more detailed explanation of the Preparation phase.
Step 3: Loading
During this phase, the prepared data is transformed to be compatible with the destination, and then loaded. For Amazon S3 destinations, data is loaded in an Append-Only fashion into the file format (.csv or .jsonl) you select during destination setup. Refer to the Loading behavior section for more info and examples.
Note: The transformations Stitch performs when loading data into Amazon S3 depends on the data storage format selected during destination setup. Refer to the Transformations section for more info.
Loading behavior
When data is loaded into an Amazon S3 destination, it will be loaded in an Append-Only fashion. This means that:
- A new CSV or JSON file for every table replicated is created during each load. A single table in the source will correspond to multiple files in the destination.
- Existing records - that is, records in files already in the destination - are never updated
- Data will not be de-duped, meaning that multiple versions of the same record may exist across multiple files in the data warehouse
Because of this loading strategy, querying may require a different approach than usual. Using some of the system columns Stitch inserts into tables will enable you to locate the latest version of a record at query time. Refer to the Querying Append-Only Tables documentation for more info.
Example: Key-based Incremental Replication
Below is an example of how tables using Key-based Incremental Replication will be loaded into Amazon S3:
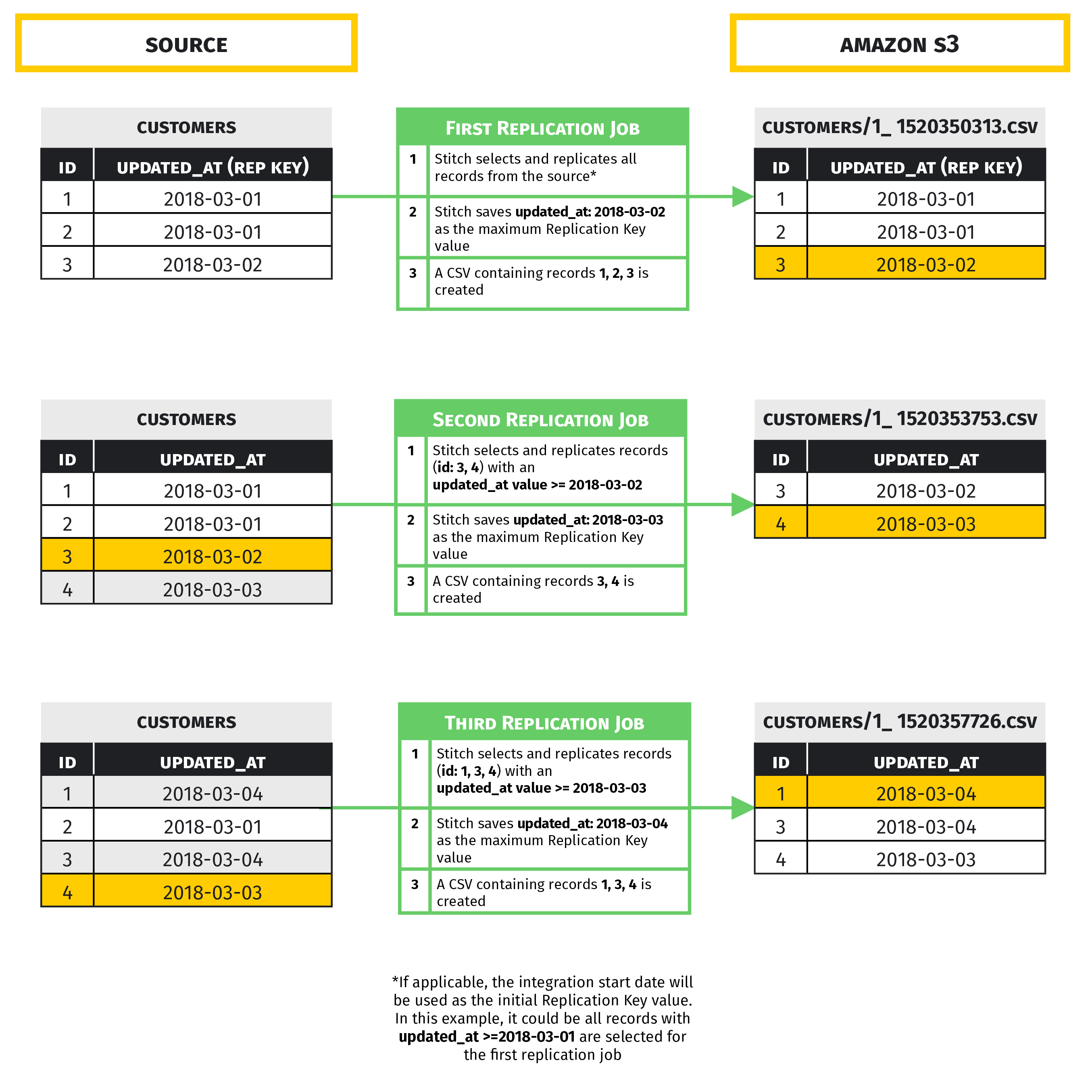
File structure
The file structure of your integrations’ data in your Amazon S3 bucket depends on two destination parameters:
- The definition of the Object Key, and
- The selected data storage format (CSV or JSON)
Object Keys and file structure
Amazon S3 uses what is called an Object Key to uniquely identify objects in a bucket. During the Stitch setup process, you have the option of using our default Object Key or defining your own using a handful of Stitch-approved elements. Refer to the Amazon S3 Setup instructions for more info on the available elements.
The S3 Key setting determines the convention Stitch uses to create Object Keys when it writes to your bucket. It also defines the folder structure of Stitch-replicated data.
Below is the default Key and two examples of an Object Key that an integration named salesforce-prod might produce:
/* Default Key */
[integration_name]/[table_name]/[table_version]_[timestamp_loaded].[csv|jsonl]
/* Example Object Keys */
- salesforce-prod/account/1_1519235654474.[csv|jsonl]
- salesforce-prod/opportunity/1_1519327555000.[csv|jsonl]
As previously mentioned, the S3 Key also determines the folder structure of replicated data. In the AWS console, the folder structure for the salesforce-prod integration would look like the following:
.
└── salesforce-prod
└── account
| └── 1_1519235654474.[csv|jsonl]
└── opportunity
| └── 1_1519327555000.[csv|jsonl]
└── _sdc_rejected
└── 1_[timestamp].jsonl
└── 1_[timestamp].jsonl
Data storage formats
Stitch will store replicated data in the format you select during the initial setup of Amazon S3. Currently Stitch supports storing data in CSV or JSON format for Amazon S3 destinations.
The tabs below contain an example of raw source data and how it would be stored in Amazon S3 for each data storage format type.
{
"contacts":[
{
"id":2078178,
"name":"Bubblegum",
"phone_numbers":[
{
"mobile":"0987654321",
"work":"7896541230"
}
],
"personas":[
{
"id":"persona_1",
"type":"Princess"
},
{
"id":"persona_2",
"type":"Heroine"
}
],
"updated_at":"2018-01-01T00:59:16Z"
}
]
}
Top-level Table
In Amazon S3, this data would create a file named contacts/1_[timestamp].csv, which would look like this:
| id | name | phone_numbers__mobile | phone_numbers__work | updated_at |
| 2078178 | Bubblegum | 0987654321 | 7896541230 | 2018-01-01T00:59:16Z |
While objects (like phone_numbers) will be flattened into the table, arrays are handled differently.
Subfiles
Arrays will be de-nested and flattened into subfiles. In this example, the name of the file would be contacts/personas/1_[timestamp].csv:
| _sdc_source_key_ id | _sdc_level_0_id | id | type |
| 2078178 | 0 | persona_1 | Princess |
| 2078178 | 1 | persona_2 | Heroine |
For more info and examples on how Stitch flattens nested data structures, refer to the Nested Data Structures guide.
With the exception of the _sdc columns, Stitch will store replicated data intact as .jsonl files. In this example, the name of the file would be contacts/1_[timestamp].jsonl:
{
"id":2078178,
"name":"Bubblegum",
"phone_numbers":[
{
"mobile":"0987654321",
"work":"7896541230"
}
],
"personas":[
{
"id":"persona_1",
"type":"Princess"
},
{
"id":"persona_2",
"type":"Heroine"
}
],
"updated_at":"2018-01-01T00:59:16Z",
"_sdc_extracted_at":"2018-01-01T01:10:53Z",
"_sdc_received_at":"2018-01-01T01:10:53Z",
"_sdc_batched_at":"2018-01-01T01:11:04Z",
"_sdc_table_version":0,
"_sdc_sequence":1514769053000
}
Incompatible sources
No compatibility issues have been discovered between Amazon S3 and Stitch's integration offerings.
See all destination and integration incompatibilities.
Transformations
Note: Aside from these transformations, the data loaded into Amazon S3 is in its raw form.
System tables and columns
Note: This applies to all data storage formats.
For every integration you connect, an _sdc_rejected folder will be created in the integration’s directory in Amazon S3. For every load where a rejection occurs, a .jsonl file containing data about the rejection will be placed in the _sdc_rejected folder. Note: These files will be .jsonl, even if .csv is selected as the file format during destination setup.
Additionally, Stitch will insert system columns (prepended with _sdc) into each file (.csv or .jsonl) created for each table.
JSON structures
How JSON structures are stored in Amazon S3 destinations depends on the data storage format selected during destination setup:
-
CSV: Nested JSON structures will be flattened into relational objects. This means that nested maps (JSON objects) will be flattened into the CSV file, and nested records (JSON arrays) will be de-nested into subfiles.
-
JSON: Nested JSON structures are stored as-is, as all data is stored in JSON files.
Refer to the Data storage formats section for examples of how nested data will be stored for each data storage format.
Compare destinations
Not sure if Amazon S3 is the data warehouse for you? Check out the Choosing a Stitch Destination guide to compare each of Stitch’s destination offerings.
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.