Skip Navigation
If your business is like most, you have no problem collecting data. The problem lies in putting that data to good use and gleaning valuable insights that can help drive better decisions. Resolving that challenge requires finding a data integration tool that can manage and analyze many types of data from an ever-evolving array of sources. But before that data can be analyzed or used to derive value, it must first be extracted.
In this article, we outline what data extraction is, look at the relationship between data extraction and data ingestion (using a process called ETL), and explore various data extraction methods and tools. Finally, we cover some API-specific challenges to the data extraction process, as well as how data extraction supports business intelligence to get the most value from your data.
What is data extraction?
Data extraction is the process of obtaining raw data from a source and replicating that data somewhere else. The raw data can come from various sources, such as a database, Excel spreadsheet, an SaaS platform, web scraping, or others. It can then be replicated to a destination, such as a data warehouse, designed to support online analytical processing (OLAP). This can include unstructured data, disparate types of data, or simply data that is poorly organized. Once the data has been consolidated, processed, and refined, it can be stored in a central location — on-site, in cloud storage, or a hybrid of both — to await transformation or further processing.
Data extraction examples and use cases
Suppose an organization wants to monitor its reputation in the marketplace. This may require many different sources of data, including online reviews on web pages, social media mentions, and online transactions. An ETL tool can extract data from these various sources and load it into a data warehouse where it can be analyzed and mined for insights into brand perception.
Other examples where data extraction can benefit businesses include gathering various types of customer data to get a clearer picture of customers or donors, financial data to help businesses track performance and adjust strategy, and performance data, which can help improve processes or monitor tasks.
Streamline your data extraction process
Data extraction and ETL
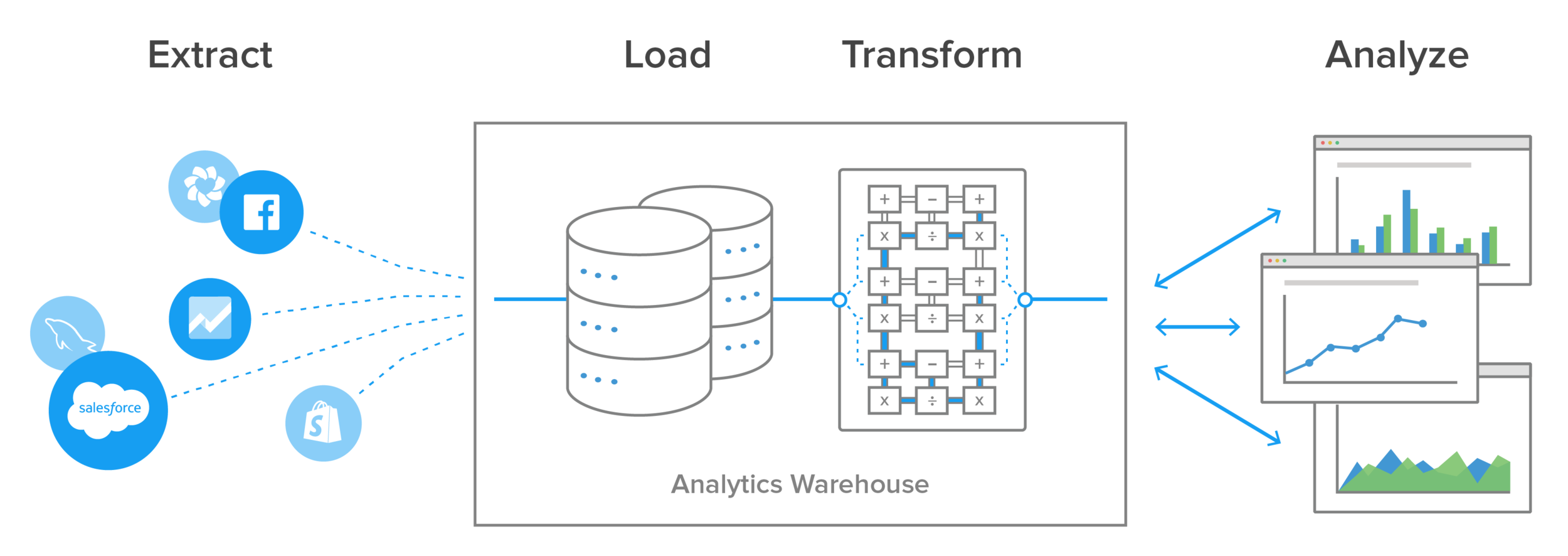
Data extraction is the first step in two data ingestion processes known as ETL ( extract, transform, and load) and ELT (extract, load, transform). These processes are part of a complete data integration strategy, with the goal of preparing data for analysis or business intelligence (BI).
Because data extraction is just one component of the overall ETL process, it’s worth a closer look at each step. The full ETL process lets organizations bring data from different sources into a single location.
Extraction gathers data from one or more sources. The process of extracting data includes locating and identifying the relevant data, then preparing to be transformed and loaded.
Transformation is where data is sorted and organized. Cleansing — such as removing missing values — also happens during this step. Depending on the destination you choose, data transformation could include data typing, JSON structures, object names, and time zones to ensure compatibility with the data destination.
Loading is the last step, where the transformed data is delivered to a central repository for immediate or future analysis.
The data extraction process
Whether the source is a database, a SaaS platform, Excel spreadsheet, web scraping, or something else, the process to extract information involves the following steps:
- Check for changes to the structure of the data, including the addition of new tables and columns. Changed data structures have to be dealt with programmatically.
- Retrieve the target tables and fields from the records specified by the integration’s replication scheme.
- Extract the appropriate data, if any.
Extracted data is loaded into a destination that serves as a platform for BI reporting, such as a cloud data warehouse like Amazon Redshift, Microsoft Azure SQL Data Warehouse, Snowflake, or Google BigQuery. The load process needs to be specific to the destination.
API-specific challenges
While it may be possible to extract data from a database using SQL, the extraction process for SaaS products relies on each platform's application programming interface (API). Working with APIs can be challenging:
- APIs are different for every application.
- Many APIs are not well documented. Even APIs from reputable, developer-friendly companies sometimes have poor documentation.
- APIs change over time. For example, Facebook’s “move fast and break things” approach means the company frequently updates its reporting APIs – and Facebook doesn't always notify API users in advance.
Data extraction methods
Extraction jobs may be scheduled, or analysts may extract data on demand as dictated by business needs and analysis goals. There are three primary types of data extraction, listed here from most basic to most complex:
Update notification
The easiest way to extract data from a source system is to have that system issue a notification when a record has been changed. Most databases provide an automation mechanism for this so that they can support database replication (change data capture or binary logs), and many SaaS applications provide webhooks, which offer conceptually similar functionality. An important note about change data capture is that it can provide the ability to analyze data in real time or near-real time.
Incremental extraction
Some data sources are unable to provide notification that an update has occurred, but they are able to identify which records have been modified and provide an extract of those records. During subsequent ETL steps, the data extraction code needs to identify and propagate changes. One drawback of incremental extraction technique is that it may not be able to detect deleted records in source data, because there's no way to see a record that's no longer there.
Full extraction
The first time you replicate any source, you must do a full extraction. Some data sources have no way to identify data that has been changed, so reloading a whole table may be the only way to get data from that source. Because full extraction involves high volumes of data, which can put a load on the network, it’s not the best option if you can avoid it.
Learn more about the next generation of ETL
Data extraction tools
In the past, developers would write their own ETL tools to extract and replicate data. This works fine when there is a single, or only a few, data sources.
However, when sources are more numerous or complex, this approach becomes time-consuming and does not scale well. The more sources there are, the higher the likelihood that something will require maintenance: How does one deal with changing APIs? What happens when a source or destination changes its format? What if the script has an error that goes unnoticed, leading to decisions being made on bad data? It doesn’t take long for a simple script to become a maintenance headache.
The good news is that data extraction doesn’t need to be a painful procedure for you or for your database. Cloud-based ETL tools allow users to connect both structured and unstructured sources of data to destinations quickly without writing or maintaining code, and without worrying about other pitfalls that can compromise data extraction and loading. In turn, it is then easier to provide access to data to anyone who needs it for analytics, including executives, managers, and individual business units.
Data extraction drives business intelligence
To reap the benefits of analytics and BI programs, you must understand the context of your data sources and destinations, and use the right tools. For popular data sources, there’s no reason to build a data extraction tool. Open source tools like Stitch offer an easy-to-use ETL tool to replicate data from sources to destinations. This makes the job of getting data for analysis faster, easier, and more reliable. With Stitch, businesses can spend time getting the most out of their data analysis and BI programs instead of building data pipelines.
Stitch makes it simple to extract data from more than 130+ different sources and move it to a variety of target destinations. Sign up for a free trial and get your data to its destination in minutes.
Give Stitch a try, on us
Stitch streams all of your data directly to your analytics warehouse.
Set up in minutesUnlimited data volume during trial